大规模预训练模型需要大型 benchmark 来进行验证。
在 Jeff Dean 等人 Pathways 架构的首个模型 PaLM 中,研究人员在一个名为 BIG-Bench 的大模型专用基准上与其他算法进行了多项任务测试。近日,谷歌终于将 BIG-Bench 的论文和 GitHub 公开出来。
研究人员表示,该工作历经两年努力完成,论文长达 100 页,作者有 442 人,目前 benchmark 包含的任务已经从 PaLM 论文时期的 150 个增加到超过 200 个。

BIG-bench 是一套用于各种规模语言模型评估的新基准测试,谷歌 AI 负责人 Jeff Dean 点赞了这一工作。
论文《Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models》

论文链接:https://arxiv.org/abs/2206.04615
GitHub:https://github.com/google/BIG-bench
随着规模的不断扩大,语言模型展示了定量改进和新的定性能力。尽管它们具有潜在的变革性影响,但其表现出的新功能特征仍然很差。为了给未来的研究提供更多信息,为颠覆性的新模型能力做好准备,了解语言模型当前和近期的能力和局限性至关重要。为了应对这一挑战,谷歌提出了超越模仿游戏基准(Beyond the Imitation Game Benchmark,BIG-bench)。
BIG-bench 目前由 204 个任务组成,获得了来自 132 个研究机构的 442 位作者贡献。该基准的任务主题多种多样,涉及语言学、儿童发展、数学、常识推理、生物学、物理学、社会偏见、软件开发等领域的问题。BIG-bench 专注于被认为超出当前语言模型能力的任务。谷歌在 BIG-bench 上评估了 OpenAI 的 GPT 系列模型、谷歌内部的密集 transformer 架构和 Switch 式稀疏 transformer 的行为,模型规模跨越数百万到数千亿个参数。
此外,还有一组人类专家执行过所有任务,以提供较准确的基线水平。目前对于各类模型的调查结果包括:模型性能和校准都随规模而提高,但绝对值(absolute term)较差(与评估者性能相比);不同类模型的性能非常相似,但稀疏性有性能增益;逐步和可预测地改进的任务通常涉及大量的知识或记忆部分,而在关键规模上表现出「突破性」行为的任务通常涉及多个步骤或脆弱的指标;在具有模糊背景的环境中,社会偏见通常会随着模型规模的扩大而增加,但可以通过 prompting 来改善。
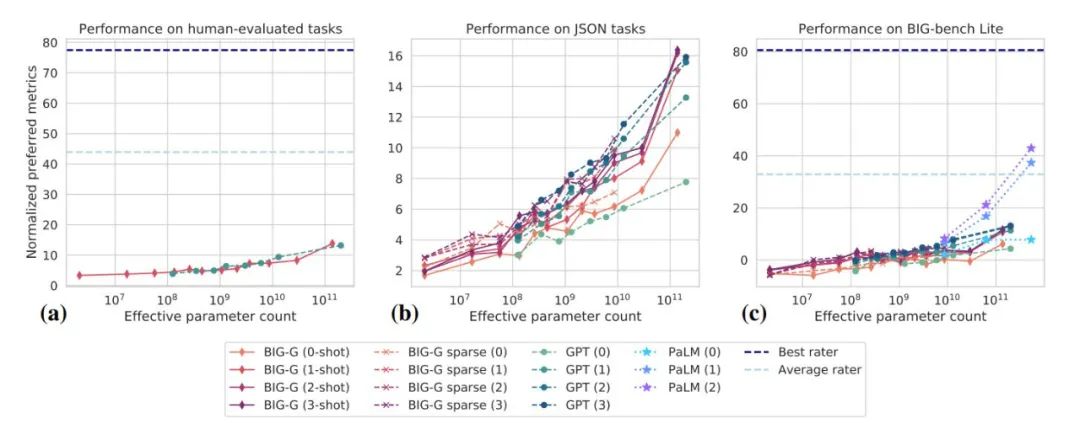
图 1:在 BIG-bench 上,很多模型总体性能随着体量的增加而提高。但目前看来,所有模型在绝对值(absolute term)方面都表现一般。
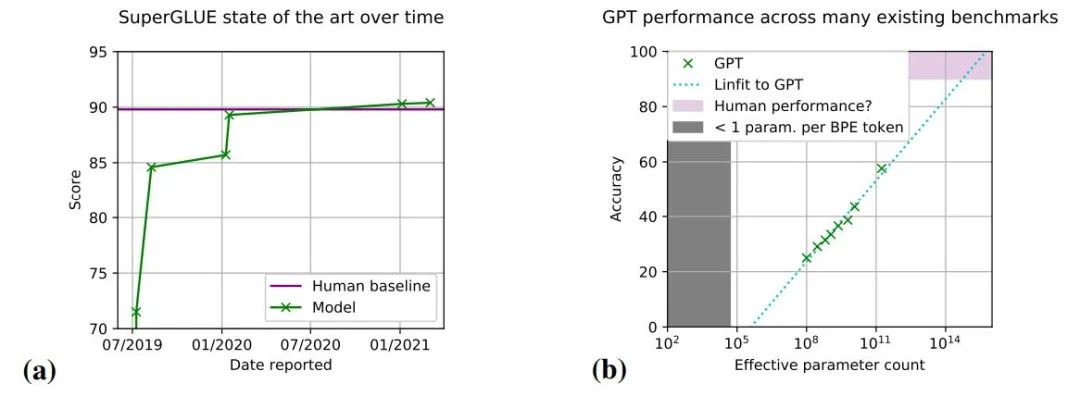 图 2:现有基准测试的范围很窄,并且表现出快速饱和的性能。
图 2:现有基准测试的范围很窄,并且表现出快速饱和的性能。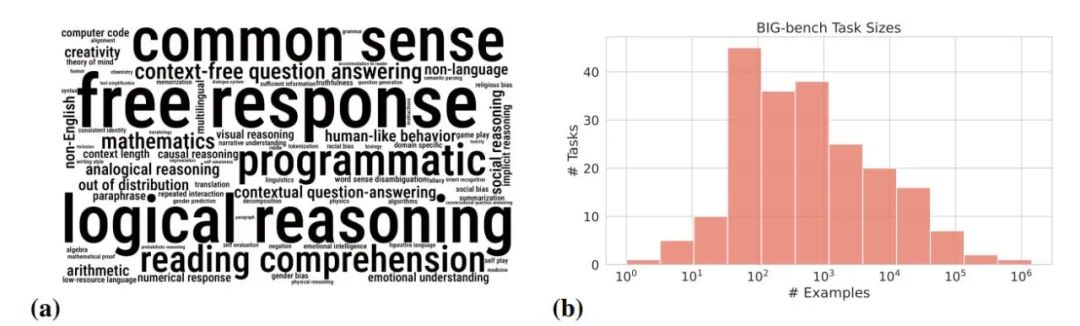
图 3:BIG-bench 任务的多样性和规模。(a)任务关键词的词云。(b)以样本数量衡量的任务规模分布。
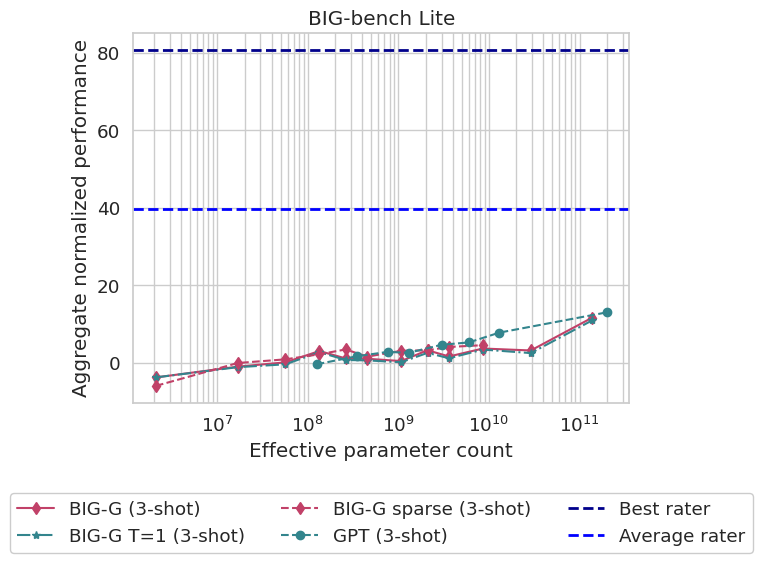
BIG-bench Lite (BBL) 是来自 BIG-bench 的 24 个不同 JSON 任务的一小部分,旨在提供模型性能的规范度量,同时比 BIG-bench 中的 200 多个编程和 JSON 任务的全套评估轻便得多。BBL 上当前模型性能的排行榜如上图所示。
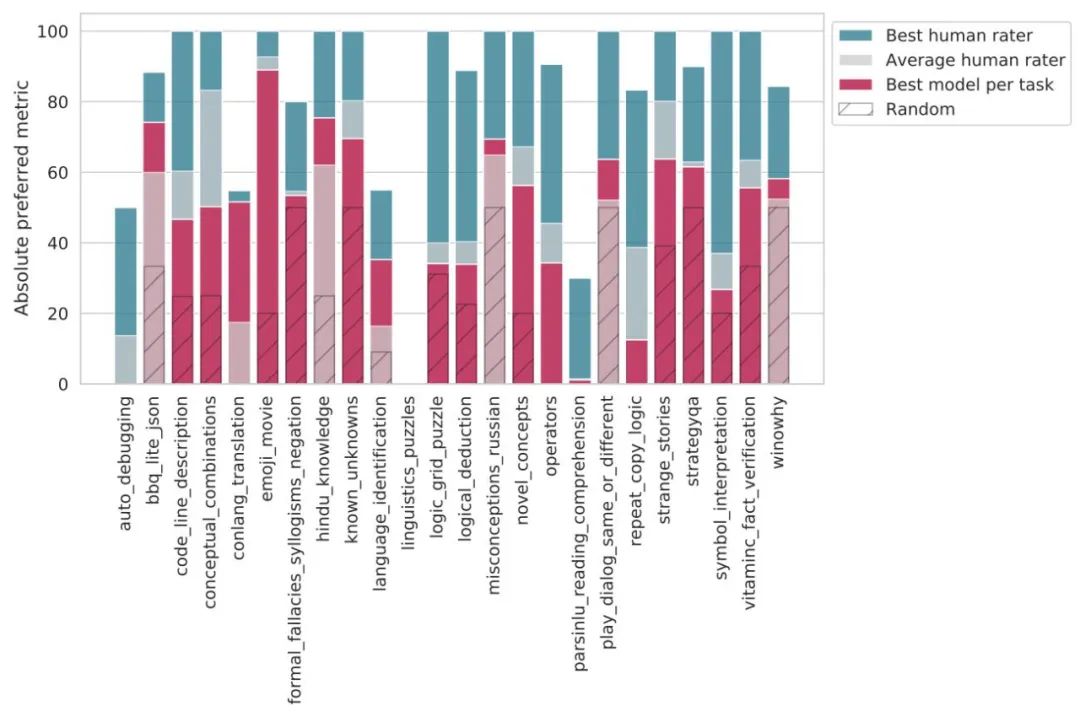
图 4:每个 BIG-bench Lite 任务上的最佳(蓝色)和平均(灰色)人类得分,以及最佳模型配置(栗色)的 BIG-bench Lite 性能。多项选择任务的随机性能由影线标记表示。
谷歌鼓励社区参与者继续提交新的任务,并表示任务将被逐一审查并以滚动方式合并到 BIG-bench 存储库中。任务作者也将包含在未来出版物的作者列表中。