可谓是「无心插柳柳成荫」。
在 Kaggle 的世界,软件开发者、金融模式和行为研究公司 Deep trading 的创始人 Yam Peleg 称得上一位「大神」。目前,他在 Notebooks Grandmaster 中排名第 11,在 Discussion Grandmaster 中排名第 5。
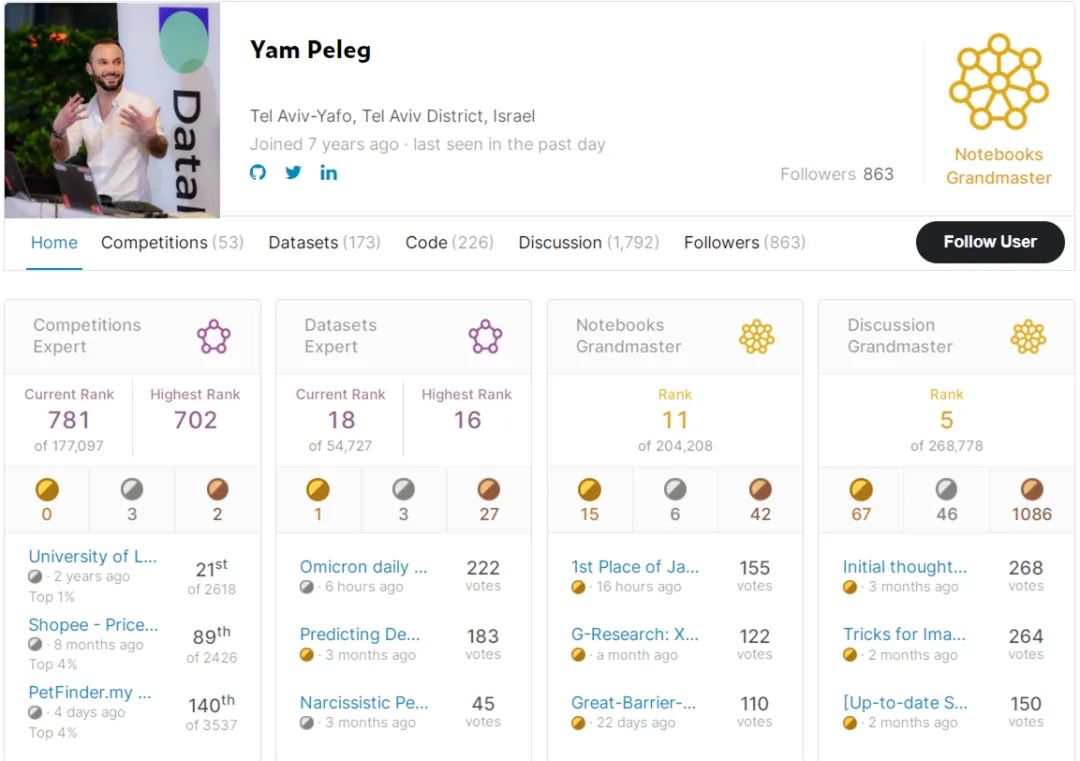
最近,他干的一件事在 reddit 上引发了网友热议:他训练了 2021 年的每一个 SOTA 模型,并在最近的一项 Kaggle 图像分类比赛中意外斩获了一枚银牌。这项 Kaggle 比赛名为「Pawpularity Contest」,这是一个典型的多模态回归问题,根据宠物图片来预测它们的可爱程度。

图源:https://www.kaggle.com/c/petfinder-pawpularity-score
他的思路是这样的:训练每个 SOTA 模型,使用 100 亿参数的集合的集合(ensemble of ensembles)来「核武攻击」(Nuke)Kaggle 比赛的排行榜。
对于这一策略(trick)的命名 ——「Nuke option」,网友表示非常喜欢,并将在其他比赛中用这一命名。

另一位网友称赞道,「在 Kaggle 环境中完成所有事情真了不起。」
方案解读
根据 Yam Peleg 的 Notebook 介绍,他训练的模型包括如下:
EfficientNet
NFNet
ViT
Swin Transformer
Deep Orthogonal Fusion of Local and Global Features(DOLG)
Hybrid Swin Transformer
External Attention Transformer(EAT)
他将自己的方案称为「Nuclear Protocols for Image Classification」,并表示只有用尽了其他方案才考虑使用。pipeline 如下图所示:提出的方法是 7 个堆叠 pipeline(140 + 模型)的集合,并且每个 pipeline 都有一个在提取图像嵌入上训练的第二阶段(2nd)模型。

实现步骤
训练这些 SOTA 模型之前,Yam Peleg 首先导入库:

接着安装其他配置,完成数据填充(seeding):
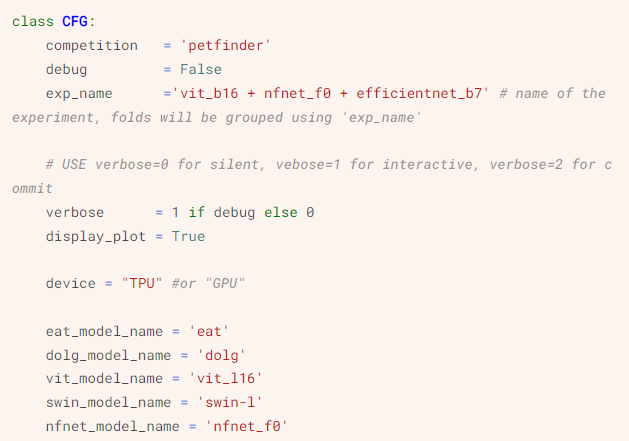
 配置部分截图
配置部分截图然后是 TPU 配置、加载元数据、CV 的分层 K 折回归(Stratified KFold for Regression)、增强(Augmentations)等步骤。数据 pipeline 如下所示:
读取原始文件,然后解码到 tf.Tensor
按需求重新调整图像大小
将数据类型变为 float32
缓存数据以提升速度
使用增强来降低过拟合,并使模型更稳健
将数据分割为 batch
最后依次训练模型,并将 Notebook 提交至了 Pawpularity Contest 中,获得了一枚银牌。

完整排行榜:https://www.kaggle.com/c/petfinder-pawpularity-score/leaderboard