今天,分享一篇独家丨李志飞将在大模型领域创业,做中国的 OpenAI,希望以下独家丨李志飞将在大模型领域创业,做中国的 OpenAI的内容对您有用。

摘要
ChatGPT 的爆火点燃了 AI 大模型时代,李志飞告诉极客公园,自己将全力投入其中。
ChatGPT 爆火后,新的共识正在逐渐形成:语言大模型将成为下一个科技时代的超级加速器。中国也需要自己的 AI 大模型。而有能力做这件事的人选并不多,李志飞是其中之一。
作为科技创业圈最资深的自然语言科学家之一,李志飞出身美国约翰霍普金斯大学语言与语音处理实验室,博士期间一直研究机器翻译和自然语言处理。离开大学后,李志飞加入谷歌 AI 团队,主导开发了包括谷歌手机版离线翻译等一系列产品。2012 年,他选择回国,在语音交互领域创业,创立出门问问。
ChatGPT 火起来之后,他一个月两次前往硅谷,和来自 Open AI、谷歌、DeepMind 等各家的工程师和科学家交流取经。「AI 大模型的元年」来了,这是他最直观的感受。一番调研之后,他明白这场大模型之战,参赛选手不止巨头,也不会是只有一两个幸存者的「生存游戏」。
语言模型、人机交互,变革发生在李志飞学习、研究、工作了十几年的领域。他告诉极客公园,已经下定决心投身其中,做一个中国的语言大模型。
「我一直想做一个我能做,我喜欢做,同时也有深远价值的事情。」他表示,早在 2020 年 GPT-3 刚发布时,他就提出 GPT-3 是「暴力美学」的胜利,看到了通往 AGI 的可能性,并最早着手开发 GPT-3 中文版 UCLAI。
近日,李志飞和极客公园进行了一场近两个小时的交流,分享了自己对大模型、ChatGPT 的看法,以及自己接下来在这个领域创业的思路。
以下是对话实录,由极客公园整理。
01
「这就是 AI
大模型时代的开启」
极客公园:怎么理解这场 ChatGPT 带来的狂热浪潮?新在什么地方?为什么大家现在这么兴奋?
李志飞 :ChatGPT 始于一个基于统计的语言模型,通过千亿级参数的训练,让它拥有了各种能力,可以快速学会各种任务。这次普通老百姓都体验到,ChatGPT 在语言表达、回答知识性的问题、多轮对话的上下文逻辑等方面的表现,带来的体验超出所有人的期望。它可以编程、做算术题、写诗,甚至某种程度上比真人做得都要好。
极客公园:除了震惊的体验本身,在创业者或者资本看来,是怎么把它看成一个变革性的商业机会的?
李志飞 :我过年第二天就再次跑到美国去,初衷就是想了解有没有人清楚这是怎么搞出来的,为什么大模型这么厉害。
我跟 Google、OpenAI、DeepMind、Meta、Amazon 的人聊,即使技术大牛都还不清楚 ChatGPT 如何拥有这种能力。但是大家能够看到很多现象。第一,用户太疯狂了;第二,美国太疯狂了,在美国知名孵化器 Y Combinator,可能有三分之一以上的项目都是基于大模型做的应用。
所有人都认为,这是 AI 大模型时代的开启,就像 2010 年移动互联网时代一样。不到硅谷,切身感受到 AIGC 的火热,我不会下定此刻是「AI 大模型时代」这一结论。我每天七八个会从早说到晚,喉咙都是哑的,都是讨论这个东西。让你觉得这就是一个时代的开端。
 图片来源:DeepMind
图片来源:DeepMind极客公园:对这个时间节点,很多人将其比作移动互联网的 iPhone 时刻。大家已经想清楚这是一场怎样的变革了吗?
李志飞:为什么说现在 AI 大模型出来,大家像 2010 或 2011 年的时候看移动互联网一样?我 2010 年在硅谷,当年所有人都觉得移动互联网是一个大事,但所有人也都觉得商业模式不清晰,因为屏幕太小,广告做不了,而且网络信号也不好。但是当时大家看到几个东西,比如屏幕体验已经很好了,3G 通讯也能用了,在路上发邮件查餐馆虽慢一些,但是 GPS 很准。
我对现在也有这种感觉,直觉这是一个大事情。美国创投在 2022 年 10 月已经觉醒了,当时我在美国,有一位红杉的投资者跟我说,李志飞,你的时代到了。我说为啥?他说你知道吗?在美国,红杉所有的管理合伙人只讨论 AIGC,别的项目都不看了。
极客公园:今天,投资 AIGC 还是很多 VC 的看点,但最近大家对于底层 AI 大模型的热情也涨起来了。这是什么原因?
李志飞:现在很多人把 AIGC、ChatGPT、AI 大模型搅在一起。要先理清楚这三个是不同的概念。最底层是 AI 通用大模型,上面可以做 AIGC,比如说 Midjourney 可以画画,Jasper 可以写文案等;也可以基于底层模型做对话机器人,比如基于ChatGPT。在美国,除了 OpenAI 和巨头,还有另外三、四家创业公司也都在做 AI 通用大模型,都有大几亿美金的投入。
但是在中国,你突然发现,要进入 AI 大模型时代,根本就没有一个基本的、能玩得好的 AI 大模型,怎么做应用?如果现在是移动互联网的开端,安卓、 iOS 是不是超级重要?但是今天中国缺乏大模型时代的安卓、 iOS,所以根本没法开发应用。即使中美完全畅通,以今天中国科技的发达程度,以及资本的力量,AI 大模型肯定也是一个必须的基础设施。
极客公园:AI 大模型就是 AI 时代的操作系统级别的存在?
李志飞:我不太想把它比作操作系统,也不想把现在看成 iPhone 时刻或者网景时刻。因为我觉得所有这些比喻,都会让我们错误地去判断这个事情。如果把它比作操作系统,按历史看我们会觉得中国肯定没戏;如果把现在看成网景时刻或 iPhone 时刻,那创业者应该选择去做一个网站或移动 APP,但现在中国缺的反而的是一个大模型时代的浏览器或 iPhone。
另外从形态来讲,无论是浏览器,还是硬件,还是安卓 iOS,都是一个离线的东西,或者是一个静态的东西。
AI 大模型是一个跟数据、业务高度融合,需要动态迭代发展的一个存在,它是个 service,下面不停在变,和应用深度的融合。它远远比当年静态的事物要更加有多样性,有更多可能性。
极客公园:更接近一个新时代的云。
李志飞 :我觉得比喻成智能云 OS 更好一点,这是一种整合的流动的 Service。凡是离线的、硬件的、实体的来类比,AI 大模型都会被带偏。任何对它历史形态的简单归纳,都有可能束缚对于它的正确理解。
02
「它可能让整个
价值链都重新塑造」
极客公园:既然不能做定义,怎么理解目前 AI 大模型展现出的超强能力和想象空间?
李志飞:在我看来,它是一个「通用的认知引擎」。首先它有超强的语言能力,在学习语言的过程中,也学习了很多知识和逻辑。有了这些基本能力后,就能快速拥有做各种任务的能力。
比如说只需要给它少量的数据,就能够做翻译。本来它只懂中文,但如果你给了一万个中英互译的例子,它就能够很快做好翻译。就像打通任督二脉一样,它很快就能够自己把能力串通。
所以这个认知大模型的能力会带来很多可能性。比如拿现在的大模型加一些蛋白质结构的数据,它展现出来的预测结构的能力,很可能就比不是基于语言大模型的其它模型效果要好得多。
极客公园:为什么通用大模型会有这么强大的潜力?
李志飞:模型学会了非常底层的结构和机制。万物都是自然产生的,语言也好,生物结构也好,它一定符合某种我们目前难以解释的规律。模型经过互联网上所有的数据训练之后,它也获得了某种属于自己的解读方式。
极客公园:这种能力是通过学习语言获得的吗?
李志飞:语言是底层的突破,如今通用性表现在,这个系统能够通过语言模型,做各种各样的任务。以前的语言模型只能做某一个具体任务。比如有一个训练好的预训练模型,有潜力做很多任务,但是一旦进行 Fine Tuning (微调)之后,就只能做一个任务了。微调让它处理任务的准确率更高,但却是以丧失多任务能力为代价的。
现在的通用大模型,即使进行了微调后,依旧可以做多个任务。预训练的核心是让它有基础的认知和逻辑能力,通过微调引导,让它能够在各项任务上处理得更好,知道怎么使用已有的知识。
极客公园:就像让一个人上完大学之后,获得了基础能力,然后可以从事不同的岗位,做不同的事情。而不是在幼儿园的时候,就开始训练它拧螺丝。
李志飞:这个比喻很对。以前做某个单独任务,比如机器翻译,就像一上来就教它拧螺丝。当然这也需要一定的语言逻辑和知识能力。但是如果第一天只教了拧螺丝,比起先让它读大学,然后再教它拧螺丝,可能后者拧得更好。第一是学得快速高效,比如之前可能要教 5 年,现在只要教 5 天就行了。第二,不但可以拧螺丝,还可以教它写论文,做教授。只要用很少量的例子,就可以让它快速学习。
极客公园:这样通用大模型的出现,对于 AGI(通用人工智能)意味着什么?
李志飞:今年可以说是 AI 通用大模型的元年。对于 AGI 来说,我认为是明确有光,越来越逼近,也可能永远都不能到达。今天人类的智能可能也没有被挖掘充分。AGI 的天花板可能是人类集体智能的一个集合。如果你把全世界每一个人具备的能力,以及特异的东西都聚合在一起,看成一个抽象统一体,这就通向集体智能。
如果这样假设,现在是这个阶段的起点。
极客公园:如果说现在我们能够看到基于 AI 带来的全新生产力。它会给现实带来怎样的影响?
李志飞:现在 ChatGPT 或 AIGC,还存在于虚拟世界,帮助人类提升效率,比如自动化一些步骤、做一些重复的工作,或者给一些脑暴 idea。未来三五年,都是人的得力助手。
 图片来源:DeepMind
图片来源:DeepMind我们为什么觉得它厉害,后面的应用可能远超互联网,因为这是一个「通用的认知模型」。一旦把这个方法论、基础放到不同领域,可能会重塑很多东西。
我觉得它可能真的会让整个价值链都重新塑造。比如对于程序员,以后可以用自然语言沟通,提供数据,模型直接写程序。这可能就会导致计算范式产生巨大的改变,操作系统、分布式计算、甚至芯片本身的大部分工作,都会从程序驱动变成数据驱动。这种改变发生以后,今天还有生意的一部分企业,可能再过 10 年就没生意了。
03
「AI 通用大模型
是一个核武器,
它是有时间窗口的」
极客公园:2020 年 GPT-3 出来的时候,大家挺震撼的,国内也热过一波。在那个变化发生的时候,大家没有去把它持续不断地做好,是因为什么?
李志飞:抽象地说,第一,没有对于 AGI 的信仰;第二,就算你有信仰,像我这种已经产生的信仰,并且当时也训练了 GPT-3 中文版 UCLAI,但还是不够坚决;第三,到执行层面,也没有足够的钱;第四,没有一个有真实用户的线上大模型,就没有产品和数据闭环。GPT-3 从 2020 年已经在线上跑了,拿到数据,然后每个星期重新优化迭代。
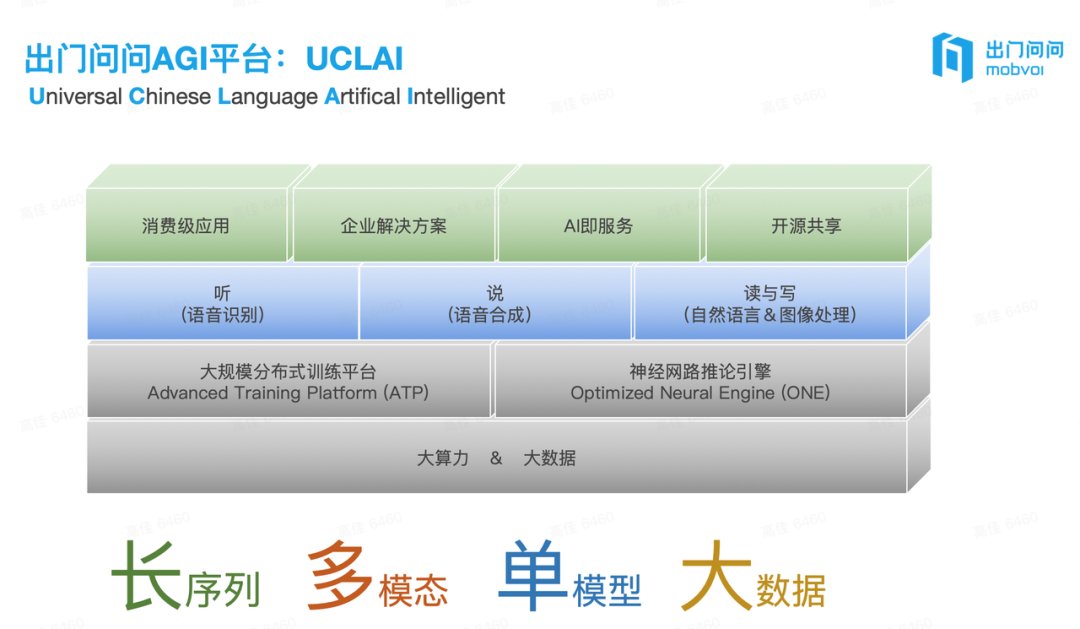 GPT-3 中文版 UCLAI | 图片来源:出门问问
GPT-3 中文版 UCLAI | 图片来源:出门问问极客公园:在国内,功能性、专用的 AI 很早就在各个场景里应用了,但是大家更多去考虑应用场景,而没有对大模型的革命力有更多的想象。
李志飞:对,刚才只是讲了一些抽象的东西。整个土壤不一样,土壤孕育的人也不一样。人和钱都很重要。比如美国,有一批财务自由的人,总是要干一些跟别人不一样、超级不确定的东西。甚至有时候非常偏执。OpenAI 前三年在毫无营收的前提下,每年烧 5 亿美金。
咱们对不确定性的东西,天然比较恐惧,但跟 10 年前比好太多了。10 年前中国是什么状况,当时我回国做中文版 Siri,做一个语音 APP,大家都觉得如神一般。如果我今天只是把 API(Application Programming Interface 应用程序编程接口)包装一下,做一个 ChatGPT,大家就会觉得山寨。因为大家已经开始认识到,需要 10 亿美金砸里边做大模型。
极客公园:如果说今天就像哥伦布已经发现新大陆,在中国我们要去复现属于自己的 AI 大模型,是怎样的难度?
李志飞:首先,我们知道新大陆肯定有金子;第二,我们大概知道路线是什么样子,但没有特别精准的地图。我们知道 LLM 能够实现,也大概知道它的原理是什么样子,但是做的过程中,肯定有无穷的风浪,有很多决定需要去做,才能够到达彼岸。
现在市场上流传着中美之间的差距是两年,或者不到两年。我觉得,如果现在有足够多的钱、算力、人,我们今天开始搞一个中文 ChatGPT,可以做到和它性能差不多或者差一点,这就是我们培养的一个大学生。人家的大学生现在已经 80 分了,我们培养的是 60 几分,只要努力,后面升到 80 分也越来越快了。
极客公园:比较而言,目前中国做 AI 大模型,有什么优势,有什么劣势?
李志飞:先说短处,对于大规模的 AI 大模型,我们的人才是非常少的,因为中国没有怎么训练出过好的大模型。过去我们的模型参数可能也很多,但不是通用的,语音识别、TTS、人脸识别都单独做一套,所以方法论也有点不一样。还是以大学生比喻,目前中国训练的大模型可能只有 40 分,没到 60 分。只有先做出一个 60 分的大模型,有了自学能力,才能靠勤奋努力升到 80 分。
同时我们也有优势,比如在数据层面,可以标注海量的数据,可以做精修;第二,如果方向很清晰,中国是很擅长「暴力美学」的。
极客公园:对于 AI 大模型,目前所有人都说不清楚商业模式、最终产品形态是什么样。在这种不清晰的状态下,在中国,做一个小一点的东西,直接通向某个目标,是不是更合适?
李志飞:我觉得,最一流、最前沿的投资者,这一时刻大概率会选择最大的东西,因为垂直领域的东西根本就不用着急。大家都知道通用 AI 大模型是一个核武器,它是有时间窗口的。人才壁垒、时间壁垒、数据壁垒、资金壁垒一旦建立起来,小的团队就没有戏了。
目前,美国做通用 AI 大模型的融资窗口就已经关了,除了 OpenAI 以外,好几家都有大几亿美金。除非有超级牛的人进来,否则不会再有 VC 再进去。
极客公园:如果未来中国也出现了一个类似 OpenAI 的大模型,以及垂直领域的细分模型,未来的产业形态会是怎样?
李志飞:肯定不会是一个大模型。在美国,可能 Amazon 会有一个,不管是自己做,还是收购,微软和 OpenAI 会有一个,Google 会有一个,创业公司还会有一两个。它是一个通用认知模型,后面还有各种各样的商业模式,比如在金融领域做一个应用的模型。但是前提是你有了一个 60 分的大学生,才能通过勤奋努力学会搞金融。
我觉得大模型的数量不会像以前互联网操作系统那样就两个,那是一个静态的东西。因为我们现在想象不出来通用大模型到底还能做出什么,在别的应用领域是不是能重塑各种各样的形态。比如制造业,可能也要有一个,但前提是要有通用大模型的能力。
04
「现在要争分夺秒
拿到参赛门票」
极客公园:如今环境在变化,有决心的人也在出现,比如王慧文。足够富裕,敢冒风险的人有了,投资人也出现了。有了这些条件后,做这件事还有哪些难点和不确定性?
李志飞:技术之外的因素,比如 CEO 和首席科学家是不是在某些决策,或者对时间的期望能够达成关键一致?比如,首席科学家要花 1 亿人民币买 1000 张显卡,三个月之后才能训练出一个参数 1000 亿的模型。如果 CEO 特别急躁,说 1 亿人民币,三个月以后还不知道能不能做出来,问一个月做出来 500 亿参数的行不行?看起来很简单的东西,如果两边的判断不一致,可能会导致下不了决心,或导致动作变形。找人工智能科学家难,怎么用好人工智能科学家更难。
高层对时间、节奏、投入的认知要达成高度一致。包括投入多少钱、多少数据、多少人、多少算力。团队之间也是一样,还会遇到很多工程选择,比如做模型,是用更多的预训练数据,还是去标注更多的数据?在模型结构里,是把所谓的 context 长度变长,还是把字符向量表示得宽一些?至少有几十个超参数需要去处理。每个超参数随便一变,就可能影响你的时间、钱、要用的 GPU,最后结果还不确定。
极客公园:巨大的工程量面前,影响结果的不确定性因素很多。
李志飞:这些 OpenAI 也不会告诉你答案,他可能尝试过很多,什么样的数据、方法论,以及投入的预算是最优解。即使他把参数给你,你可能也不一定能搞对。
所有因素,如果高层不能很好地与程序员沟通,就会有风险。还有执行层面,数据清洗得好不好;GPU 的并行训练处理得如何,使得 GPU 的利用率比较低;数据的标注质量是不是足够好;各个模块可能有几百个因素,如果一个因素没有弄好,要么浪费钱,要么训不出来。
极客公园:要处理这些问题,对于这样技术公司的 CEO 是一个巨大的考验。
李志飞:绝对的。在这一刻的起点,首席科学家肯定是最重要的。
极客公园:做这样一个领军人物,除了对技术了解,也要会杀伐决断,聚集人才,除此之外还有什么特性很重要?
李志飞:很难去概括,但是可以类比。比如在硅谷,怎么判断一个人是不是非常 technical 或者是很硅谷范儿,你只要问他几个问题就知道了。
这是认知经验带来的交流效率。学术界高手过招也是这样,比如有些问题我已经冥思苦想了很久,各种办法都试过,我知道对方也在做这个事情,我们可能只花 5 分钟交流,就能对齐答案。他可能说一个名词,说哪一篇论文是可以做这个事情的,或者哪篇论文里边哪一部分是可以解决这个问题的,你立刻就知道此人的能力层次。他能思考到这个程度,一定是一个很长的过程。哪怕我们对问题的定义不一样,双方至少在这个地方真的是深度思考过。
极客公园:怎么看目前大模型的竞争环境?时间节点是怎样的?
李志飞:如何与巨头竞争,目前还回答不了。顶级投资者更关心的是花多少钱能搞出来,是不是能做成。
在我的想象里,到明年 6 月,只要你能做出这个 60 分的基础大模型,哪怕市场上有 5 个,都能进入下一轮竞赛。现在要争分夺秒拿到参赛资格,想太多只会让你犹豫,觉得风险太大。如果是做垂直大模型或应用,一点都不要急,慢慢来。
05
现在到了我的主战场,
一定要参与
极客公园:那你自己是怎么做决定的?
李志飞:这是我的主战场,我一定要参与。我读了多年的 NLP 博士,在 Google 做的也是语言翻译相关工作,创业十年做语音交互和生成式 AI。现在 NLP 领域有如此大事,中国也需要自己的通用大模型,此时不做,更待何时。
这是我的专业,也是我的热情,同时也相信能建立深厚壁垒和深远价值。关于壁垒,我这次去美国之前总觉得 Google 是不是很容易做出 ChatGPT。但跟很多人聊完以后,我意识到这里边其实可以建立很多壁垒,Google 要立马做到 ChatGPT 这种水平也不容易。
极客公园:你也要做中国版的 OpenAI?
李志飞:中国版 OpenAI 只是让向公众描述这件事更容易。但最核心,我看好的还是「通用的认知模型」本身。两年前我就已经着手做大模型了,是国内最早开始认真做大模型的一批。
2020 年,GPT-3 刚出来我们就训练过一个大模型 GPT-3 中文版 UCLAI,在此基础上,我们做了文言文和白话文翻译、古画生成、音乐合成等方面的实践,也成功做出了业界 Top1 的配音产品「魔音工坊」等,拥有国内最好的 AIGC 用户量和营收规模,在世界范围也仅次于 Midjourney 和 Jasper。
 李志飞在IF创新大会 2021上分享GPT-3|来源:极客公园
李志飞在IF创新大会 2021上分享GPT-3|来源:极客公园极客公园:现在做大模型,你会有什么新思考?
李志飞:如果现在我再做通用大模型,得把骨架造得足够稳定,具有很强可塑性,然后再去精雕。就像造乐山大佛,有了骨架之后,再把鼻子、眼睛、手修得很漂亮。当你真的具备 60 分大学生的能力之后,我们可以通过勤奋把这个大学生培养得非常好。
在此基础上我还要创新。一切跟着 OpenAI 搞没有意义,也不一定能跟上,我们要创新。
极客公园:你创业也挺长时间了,过去的经历,对做今天这个事有什么意义吗?
李志飞:过去所有的经历,都是有益的财富。首先,让我有更精准的判断力。第二,更丰富的工程实践与综合能力。
现在做这个,我只招最厉害的人做最核心的技术。而且更有长期主义的定力,而不是做短期有进展、长期有消耗的事情。
极客公园:你曾经是科学家,创业这些年之后,有什么变化吗?你怎么定位自己?
李志飞:我是有科学家思维的 CEO。我能跟科学家、工程师深度沟通,与科学家一起制定路线,建立信念,让整个团队力朝一个方向使,这也是 OpenAI 能成功的很重要因素。
极客公园:王慧文的声势也很强,有了资金后,总能招到优秀的人。你会 care 这件事吗?
李志飞:人是最重要的因素,每一家创业团队都会有自己的核心竞争力。但第一阶段最重要的是:找到真正懂核心技术的人才,并且能用正确的方式和节奏跟他们合作。
极客公园:你是如何计划的?
李志飞:短期目标是把一个 60 分的通用大模型给做出来。中长期而言,有了 60 分的基础模型后,我会花大力去把它打磨成 80 分,从而可以在真正的商业场景里稳定使用。我的优势是对通用 AI 技术有非常浓烈的兴趣,也对未来技术会怎么演化有自己的判断和把握,这使得我能够在这个赛道里长跑。
我心中已经有清晰路线图,并看到了那个终局。























