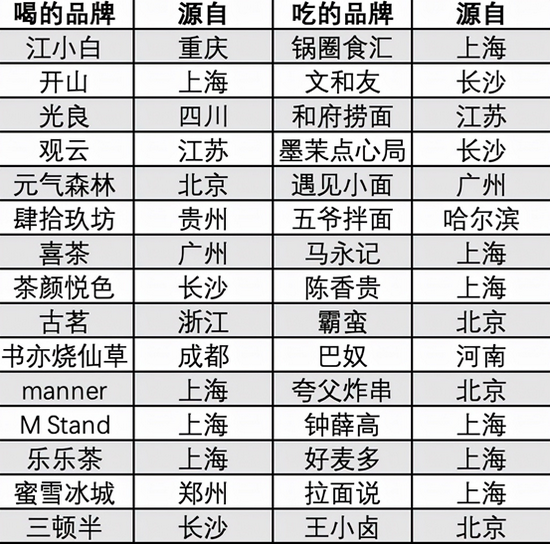
从空间到时空的视觉处理
图像中基于实例的分类、分割和对象检测是计算机视觉环境中的基本问题。与图像级信息检索不同,视频级问题的目标是在具有空间和时间维度的时空域中对对象实例进行检测、分割和跟踪。
视频域学习是基于相机和无人机的系统中时空理解的关键任务,其应用领域包括视频编辑、自动驾驶、行人跟踪、增强现实、机器人视觉等。此外,它帮助我们将时空原始数据与视频一起解码为可操作的见解,因为与视觉空间数据相比,它具有更丰富的内容。通过在我们的解码过程中添加时间维度,我们可以获得关于运动\观点变化\灯饰\遮挡\变形\局部歧义。

从视频帧。正因为如此,视频级信息检索作为一个研究领域而广受欢迎,它沿着视频理解的研究路线吸引了社区。
从概念上讲,视频级信息检索算法主要是通过添加额外的头部来捕获时间信息,从图像级过程改编而来。除了更简单的视频级分类和回归任务外,视频对象检测、视频对象跟踪、视频字幕和视频实例分割是最常见的任务。
首先,让我们回忆一下图像级实例分割问题。
图像级实例分割
实例分割不仅将像素分组到不同的语义类中,还将它们分组到不同的对象实例中。通常采用两阶段范式,首先使用区域提议网络(RPN)生成对象提议,然后使用聚合的 RoI 特征预测对象边界框和掩码。与语义分割仅对不同的语义类进行分割不同,实例分割还对每个类的不同实例进行了分割。
视频分类
视频分类任务是将图像分类直接应用于视频领域。不是将图像作为输入,而是将视频帧提供给模型进行学习。本质上,时间相关的图像序列被提供给学习算法,这些算法结合了空间和时间视觉信息的特征来产生分类分数。
核心思想是,给定特定的视频帧,我们希望从预定义的类中识别视频的类型。
视频字幕
视频字幕是通过理解视频中的动作和事件为视频生成字幕的任务,可以帮助通过文本高效地检索视频。这里的想法是,给定特定的视频帧,我们希望生成描述视频概念和上下文的自然语言。
视频字幕是一个多学科问题,需要计算机视觉(提取特征)和自然语言处理(将提取的特征映射到自然语言)的算法。
视频对象检测 (VOD)
视频对象检测旨在检测视频中的对象,它最初是作为 ImageNet 视觉挑战的一部分提出的。尽管身份的关联和提供提高了检测质量,但这一挑战仅限于用于每帧检测的空间保留评估指标,并且不需要联合对象检测和跟踪。然而,与视频级语义任务相比,没有联合检测、分割和跟踪。
图像级对象检测和视频对象检测之间的区别在于,图像的时间序列被赋予机器学习模型,其中包含与图像级过程相对的时间信息。
视频对象跟踪 (VOT)
视频对象跟踪是定位对象并在整个视频中跟踪它们的过程。给定第一帧中的一组初始检测,该算法为每个时间戳中的每个对象生成一个唯一 ID,并尝试在整个视频中成功匹配它们。例如,如果我说特定对象在第一帧中的 ID 为“P1”,则模型会尝试在其余帧中预测该特定对象的“P1”ID。
视频对象跟踪任务通常分为基于检测和无检测的跟踪方法。在基于检测的跟踪算法中,对象被联合检测和跟踪,以便跟踪部分提高检测质量,而在无检测方法中,我们得到一个初始边界框并尝试跨视频帧跟踪该对象。
视频实例分割(VIS)
视频实例分割是最近引入的计算机视觉研究课题,旨在对视频域中的实例进行联合检测、分割和跟踪。由于视频实例分割任务是受监督的,因此它需要具有预定义类别的边界框和二进制分割掩码的面向人类的高质量注释。它需要分割和跟踪,与图像级实例分割相比,这是一项更具挑战性的任务。因此,与之前的基本计算机视觉任务不同,视频实例分割需要多学科和聚合的方法。VIS 就像是当代一体化计算机视觉任务,是一般视觉问题的组合。
知识带来价值:行动中的视频级信息检索
承认视频级信息检索任务的技术边界将提高从实际角度理解业务关注点和客户需求。例如,当客户说“我们有视频并且只想从视频中提取行人的位置”时,您就会意识到您的任务是视频对象检测。如果他们想在视频中对它们进行本地化和跟踪怎么办?然后你的问题被转化为视频对象跟踪任务。假设他们还想在视频中分割它们。您现在的任务是视频实例分割。但是,如果客户说他们想要为视频生成自动字幕,从技术角度来看,您的问题可以表述为视频字幕。