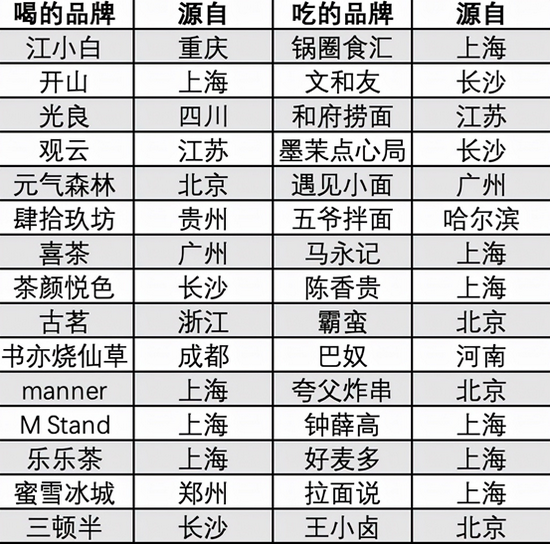
深度学习在医疗保健领域显示出很多前景,尤其是在医学成像领域,它可以用来提高诊断患者病情的速度和准确性。但它也面临着一个严重的障碍:标记训练数据的短缺。
在医疗环境中,训练数据的成本很高,这使得在许多应用中使用深度学习变得非常困难。
为了克服这一障碍,科学家们探索了几种不同程度的成功解决方案。在一篇新论文中,谷歌的人工智能研究人员提出了一种新技术,该技术使用自监督学习来训练医学成像的深度学习模型。早期结果表明,该技术可以减少对注释数据的需求,并提高深度学习模型在医学应用中的性能。

有监督的预训练
卷积神经网络已被证明在计算机视觉任务中非常有效。谷歌是一直在探索其在医学成像中的应用的几个组织之一。近年来,该公司的研究部门在眼科、皮肤科、乳房 X 线照相术和病理学等领域建立了多个医学成像模型。
“将深度学习应用于健康有很多令人兴奋的事情,但它仍然具有挑战性,因为在医疗保健等领域需要高度准确和强大的 DL 模型,”谷歌研究院的人工智能居民、自我的主要作者Shekoofeh Azizi 说。- 监督论文。
深度学习的主要挑战之一是需要大量带注释的数据。大型神经网络需要数百万个标记示例才能达到最佳精度。在医疗环境中,数据标记是一项复杂且成本高昂的工作。
“由于多种原因,在医疗环境中获取这些‘标签’具有挑战性:对于临床专家来说,这可能既耗时又昂贵,而且数据在共享之前必须满足相关的隐私要求,”Azizi 说。
对于某些情况,示例很少,首先,而在其他情况下,例如乳腺癌筛查,在拍摄医学图像后可能需要很多年才能显示临床结果。
Azizi 补充说,使医学成像应用程序的数据要求进一步复杂化的是训练数据和部署环境之间的分布变化,例如患者群体、疾病流行或表现以及用于成像采集的医疗技术的变化。
解决医疗数据短缺的一种流行方法是使用有监督的预训练。在这种方法中,卷积神经网络最初是在标记图像的数据集上训练的,例如 ImageNet。此阶段将模型层的参数调整为在各种图像中找到的一般模式。然后可以针对目标任务的一组有限的标记示例对经过训练的深度学习模型进行微调。
几项研究表明,有监督的预训练在医学成像等应用中很有帮助,在这些应用中标记数据很少。然而,有监督的预训练也有其局限性。
“训练医学成像模型的常见范式是迁移学习,其中模型首先使用 ImageNet 上的监督学习进行预训练。然而,ImageNet 中的自然图像和医学图像之间存在很大的领域转移,之前的研究表明,ImageNet 上的这种监督式预训练可能不是开发医学成像模型的最佳选择,”Azizi 说。
自监督预训练
近年来,自监督学习已成为一个有前途的研究领域。在自监督学习中,深度学习模型无需标签即可学习训练数据的表示。如果做得好,自监督学习在标记数据稀缺而未标记数据丰富的领域中可能具有巨大优势。
在医疗环境之外,谷歌开发了几种自我监督学习技术来训练神经网络以执行计算机视觉任务。其中包括在 ICML 2020 会议上提出的对比学习的简单框架 (SimCLR)。对比学习使用同一图像的不同裁剪和变体来训练神经网络,直到它学习到对变化具有鲁棒性的表示。
在他们的新工作中,谷歌研究团队使用了称为多实例对比学习 (MICLe) 的 SimCLR 框架的变体,该框架通过使用相同条件的多个图像来学习更强的表示。这在医疗数据集中经常出现,其中有同一位患者的多幅图像,尽管这些图像可能没有被标注用于监督学习。
“未标记的数据通常在各个医学领域都有大量可用。一个重要的区别是我们利用医学成像数据集中常见的潜在病理学的多个视图来构建图像对以进行对比性自我监督学习,”Azizi 说。
当自监督深度学习模型在同一目标的不同视角上进行训练时,它会学习更多的表示,这些表示对视点、成像条件和其他可能对其性能产生负面影响的因素的变化更加鲁棒。
把这一切放在一起
谷歌研究人员使用的自监督学习框架包括三个步骤。首先,使用 SimCLR 对来自 ImageNet 数据集的示例训练目标神经网络。接下来,该模型使用 MICLe 在一个医学数据集上进行了进一步训练,该数据集为每个患者提供了多个图像。最后,该模型在目标应用程序的标记图像的有限数据集上进行了微调。
研究人员在两项皮肤病学和胸部 X 射线解释任务上测试了该框架。与监督预训练相比,自监督方法在医学成像模型的准确性、标签效率和分布外泛化方面提供了显着改进,这对于临床应用尤其重要。此外,它需要的标记数据要少得多。
“使用自监督学习,我们表明我们可以显着减少构建医学图像分类模型对昂贵的注释数据的需求,”Azizi 说。特别是在皮肤科任务中,他们能够训练神经网络以匹配基线模型性能,同时仅使用五分之一的注释数据。
“这有望转化为开发医疗 AI 模型的大量成本和时间节省。我们希望这种方法能够激发对获取注释数据具有挑战性的新医疗保健应用的探索,”Azizi 说。