2016年,米哈游掏空家底,all in 游戏项目《原神》,追寻转型之路。2020年全开放式冒险游戏《原神》问世引发游戏圈现象级热议,精美的制作,3A级的画质,更是让游戏在2021年一度登顶56国排行榜。

作为一款角色养成类游戏,原神游戏本身还是还是比较肝的,再加上核心玩法较为简单,游戏后期版本更新缓慢,游戏时间久了之后部分玩家难免产生无聊,却又“食之无味,弃之可惜”的感觉。
言出法随,语音玩原神

在闲着无聊的时候,总有一些大佬的脑回路与众不同,想着整点活。这不,b站硬核整活区up主“薛定谔の彩虹猫”就通过AI算法实现语音控制原神,直接将玩家变成了神奇宝贝训练家,建议游戏改名为“精灵宝可梦:原神”。
具体战斗效果,让我们一起瞅瞅下面的动图。
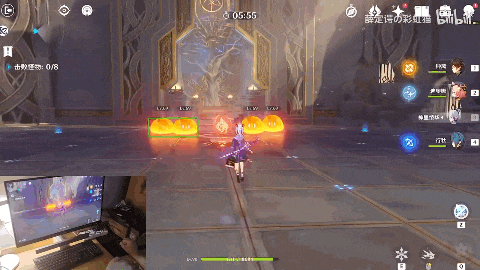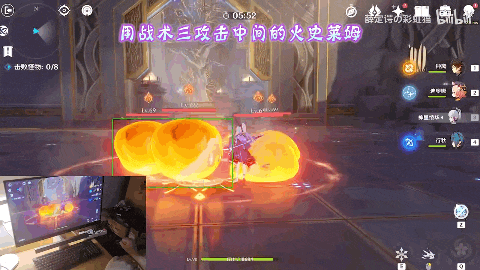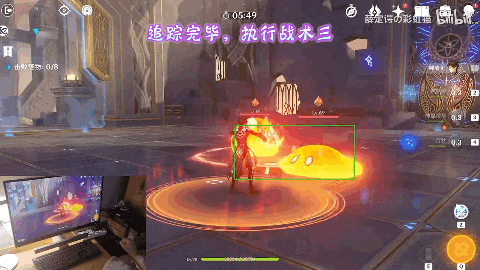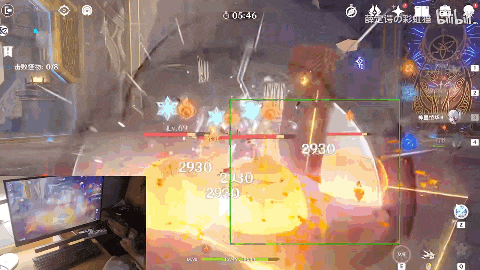
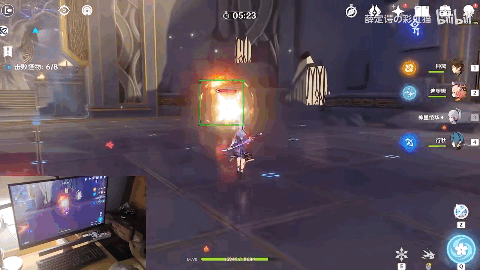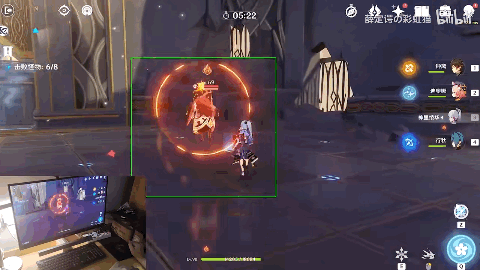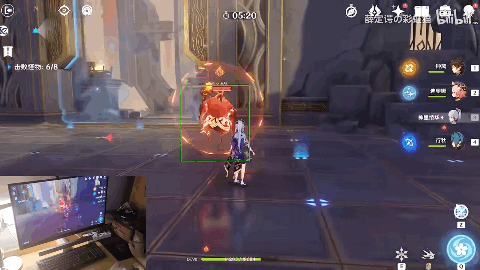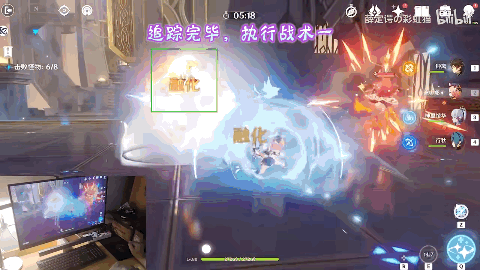
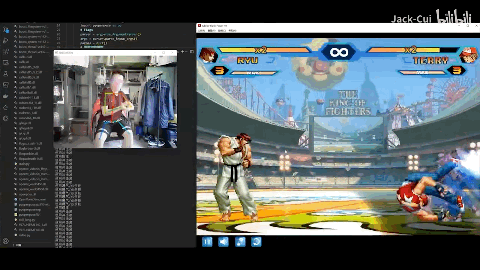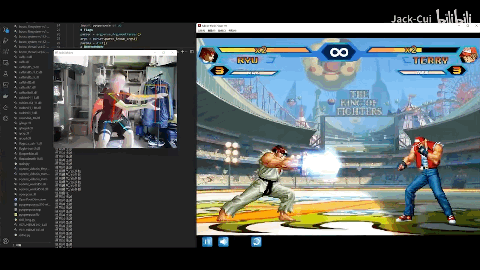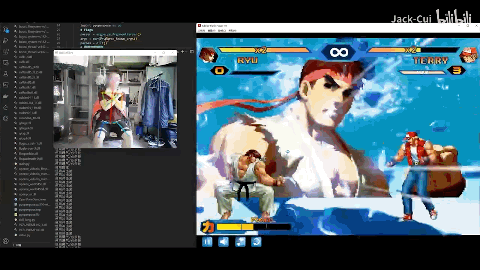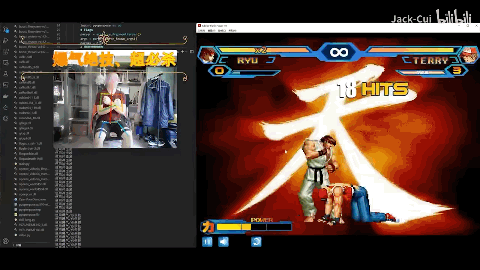
随着系统提示“在360秒内击败8只怪物”,4只火史莱姆来势汹汹。
原神训练家气定神闲喊出了一句“用战术三攻击中间的火史莱姆”,画面内出现像战斗机一样的绿色追踪框。
神里绫华向史莱姆跑去,随后切换钟离发动技能“元素战技·地心”打出aoe伤害同时套盾,随后凌华再一次登场,一招“神里流·霰步”,打出成吨元素伤害,在火史莱姆的爆炸中,结束战斗。
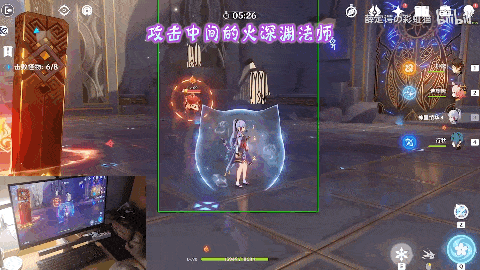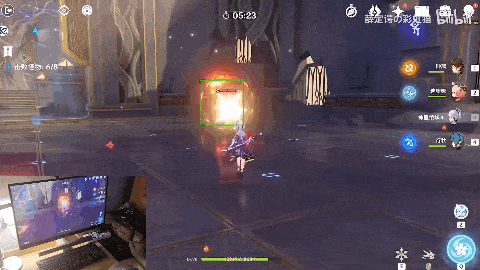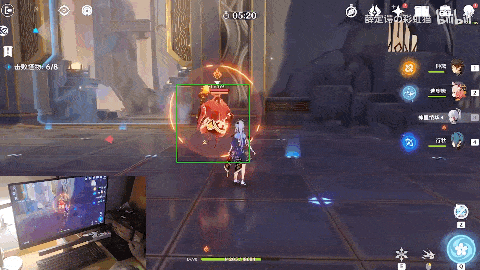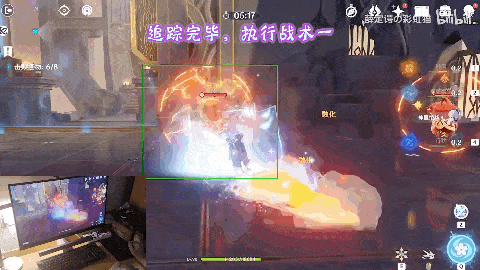
作者还预设了不同的战术方案。在应对火系深渊法师的时候。先是一句“攻击中间的火深渊法师”,角色开始自动寻怪。
来到怪物身前时,执行战术一。迪奥娜以迅雷之速使出“猫爪冰冰”技能打出伤害的同时向后方位移调整位置及套盾,再之后神里绫华登场,一招霰步欺身上前,打出combo伤害。
不过,在演示过程中,我们也发现,战术启动后的角色,其操作行云流水,非常的丝滑。但是,战术还没启动之前,却有点呆呆的,来自AI的仁慈[doge]。
那么,这种用嘴打游戏,实现言出法随,辅助玩家练就三寸不烂之舌的AI是怎样制作出来的?
三大AI工具,打造智能指令系统

视频作者“薛定谔の彩虹猫”分享了他的方法。实现AI语音玩原神,主要涉及到时下流行的“XVLM+WeNet+STARK”等三大AI主流领域。
看到这里,有的小伙伴可能会表示“说得好,这些字母拆开来我都认得,拼在一起就是我不认识的样子了。”
小伙伴们别着急额,接下来让我们一起了解下这三个工具的用处。
在以往,我们要操作游戏角色进行近战的操作逻辑是:1、看到敌方目标。2、锁定目标,向目标角色移动。3、发动攻击。
通过语音实现游戏操作,同样也是需要完成上面3个步骤。让我们一起拆解一下作者在游戏中的指令,解析这套AI的工作流。

如上图所示,当作者说出“用战术三攻击中间的火深渊法师之后”。让电脑执行了“语音指令识别——图像识别目标——角色行动”这三大步骤,整个过程有点类似于面向游戏定制了一个语音助手,就像“嘿,Siri,打开原神”。
第一步:语音指令识别

要让设备听懂我们的指令,我们就需要一个翻译官,将我们说的话转变成机器能够听得懂的计算机语言,WeNet就是我们和机器对话的翻译官。
WeNet是一个面向生产的端到端语音识别工具包,在单个模型中,它引入了统一的两次two-pass (U2) 框架和内置运行时来处理流式和非流式解码模式。其语音识别正确率、实时率和延时性都有着非常出色表现,获得了京东、网易、英伟达、喜马拉雅等公司语音识别项目的采用。
用WeNet识别咱们玩原神的语音指令,需要经过“准备训练数据”、“提取可选cmvn特征”、“生成标签令牌字典”、“准备WeNet数据格式”、“神经网格训练”、“用训练后的模型识别wav文件”、“导出模型”等6大步骤。

上面的东西用大白话讲就是,准备一些音频文件,同时标注我这些音频文件讲了啥,然后让机器去学习识别这些音频文件并生成标签。上述训练完成以后,以后我们对机器说话,WeNet就能把我们的话翻译成机器听得懂的话。
第二步:解析语音指令特征
有了WeNet的助攻之后,我们实现了说出的话让机器听得懂我们说的是啥之后,我们还要让机器将听到的东西跟画面中的东西对应上,这就轮到第二个工具“X-VLM”登场了。
X-VLM是一种基于视觉语言模型(VLM)的多粒度模型,由图像编码器、文本编码器和跨模态编码器组成,跨模态编码器在视觉特征和语言特征之间进行跨模态注意,以学习视觉语言对齐。那具体这个工具是咋实现识别对象的呢?

上图展示了X-VLM的工作流程。图片左侧为工具视觉概念的编码过程。工具包的图像编码器基于Vision Transformer实现,输入的图片会被分成patch编码。然后,给出任意一个边界框,灵活地通过取框中所有patch表示的平均值获得区域的全局表示。接着该全局表示和原本框中所有的patch表示按照原本顺序整理成序列,作为该边界框所对应的视觉概念的表示。
(字我都认识,连在一起怎么就是我不认识的样子了?)

怎么文章看着看着变成做阅读理解了,让我们再多看亿眼。

上面这段话的意思,通俗点讲就是将图片切割成方块,并且预组合这些方块。比如组合成“一个男人背着背包”的图片,或者组合成“男人背着背包过马路”的图片。
你要做的就是告诉机器这些组合和文字的对应关系,接着让设备进行机器学习。
通过这样的方式获得图片本身和图片中视觉概念(V1,V2,V3)的编码。与视觉概念对应的文本,则通过文本编码器一一编码获得,例如图片标题、区域描述、或物体标签。

这一顿操作下来,小编也被绕晕了。这玩意的作用有点像我们的眼睛,当我看到一个“书包”,虽然我没见过这个款式的,但根据特征提取,我知道这个东西就是书包,X-VLM就是这样一个工具。
X-VLM可以在接收WeNet输出的文本信息后,将图像中相关联的物件提取出来,实现语言与视觉相关联。到这里,我们可以实现让电脑知道我们说的话指的是图片里面的啥玩意了。
第三步:追踪图像
在使用了X-VLM和WeNet之后,我们成功让设备听得懂咱们说的是啥玩意了,接下来要做的就是实现“追踪目标”,听起来是不是很酷炫,有种开战斗机发射追踪导弹的感觉~
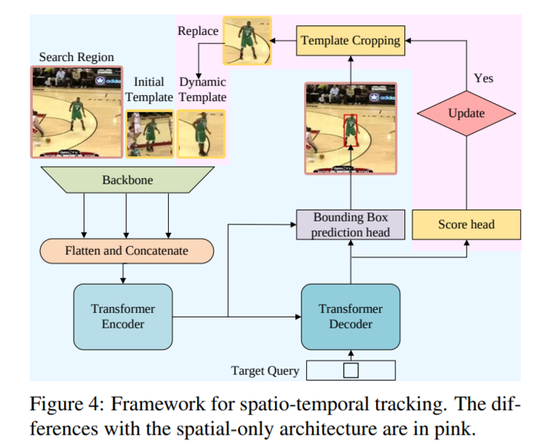
相信不少小伙伴们都猜到了,这剩下的最后一个“STARK”就是用于实现图像追踪功能的AI工具。
Stark是最新的SOTA跟踪模型,模型使用了transformer来结合空间信息以及时域信息。
模型包括一个encoder,decoder以及prediction head。其中encoder接收三个输入:当前帧图像,初始目标以及一个动态变化的模板图片。由于模板图片在追踪过程中是动态变化,不断更新的,因此encoder可以同时捕获到目标的时域和空间信息。
获取目标信息以后,工具会通过预测左上与右下角热力图的方式,在每帧图像中得到一个最优的边界框,并且可以直接在GPU端运行。

简单说就是,在我们通过X-VLM确定要追踪的目标以后,Stark就像钢铁侠Tony Stark的追踪系统一样,会记录对象在静止状态和动态状态下的样子,处理分析之后实现追踪动态对象。
那么,讲到这里,我们已经基本明白这语音玩原神三大技术的原理。那角色是怎么动起来执行战术的呢?
其实实现角色自动攻击、释放技能这一块,反而是AI语音玩原神中最容易实现的一个环节。这个功能可以通过宏指令或者代码编程来实现。小编特意到作者分享的代码文件中瞄了一眼,下面是部分代码的展示。

这一段操作代码使用python写的,逻辑也相当的简单,就是执行一串预设好的按键指令。上面图片展示的应该是对应战术一的操作。其中key跟mouse后面的数字或者字母对应了切换角色和释放技能。

代码也解释了为啥角色执行完战术之后就杵在原地发呆,因为没有了后续的指令和输入。
总的来说,如果有小伙伴想简单尝鲜一下这个AI语音玩原神,可以直接下载作者分享的代码,运行程序即可。你只需将英雄阵容及顺序设计成和作者一样,就可以达到作者视频展示的的效果了。
当然,如果小伙伴们想要玩出自己的花样,也可以直接改这段操作代码,实现不同的阵容及技能释放组合,然后记住自己改的是哪一套战术就行了。
当然,如果你想把游戏完成比较中二的,像下面这样的:

就决定是你了,神里绫华。(切换角色)
靠近敌人之后使用霰步。(释放技能)
辛苦你了,绫华,回来吧。(切换角色)
小编也帮你想好了要改哪些代码,你把对应切换角色的快捷键以及技能键替换到操作代码里面就像了,但同时你还要录一段语音到WeNet,让它进行学习,知道你在说啥。(PS:尽可能用一句话做多点事,因为AI执行比较忙,这也是为啥作者要用战术一二三的原因)
当然还有神仙大佬在视频里给出了其他的建议。比如加入SLAM工具,实现360°方位检测,让角色能够在游戏里追踪不同方位的敌人,自走地图炮了属于是。
眼睛、手势都能玩,AI玩游戏姿势还有这些
除了ai语音玩游戏外,b站还有很多大佬折腾出了别的玩游戏姿势。
[ 图片来源:哔哩哔哩所有者:Jack-Cui ]
Jack-Cui大佬直接自制ai,用一个普通摄像头加一台电脑实现体感玩街头霸王。
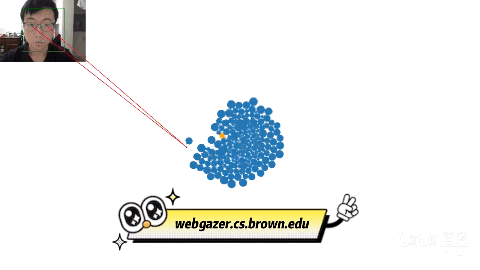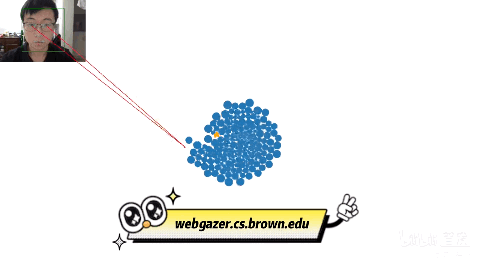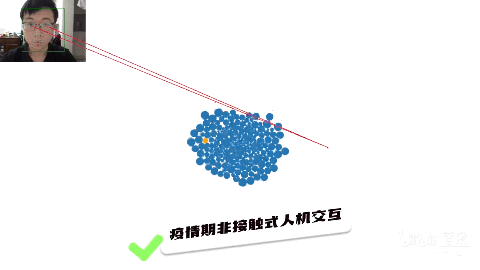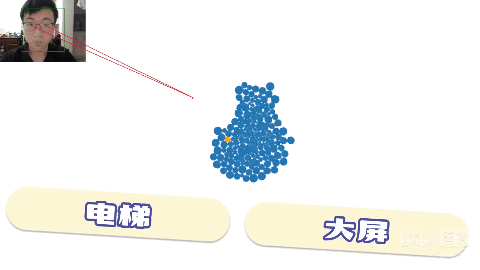
[ 图片来源:哔哩哔哩所有者:同济子豪兄 ]
b站up主同济子豪兄展示的,用WebGazer.js,实现“眼神操控鼠标”,通过眼神来玩游戏,直接就是眼神杀人术。
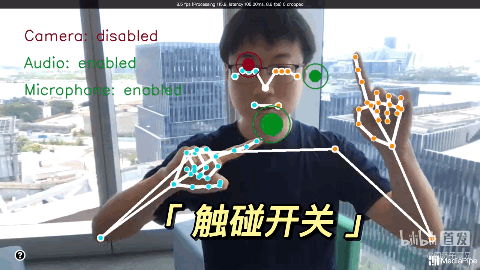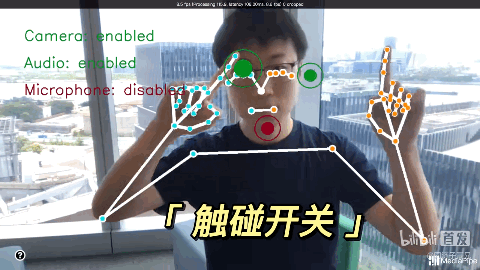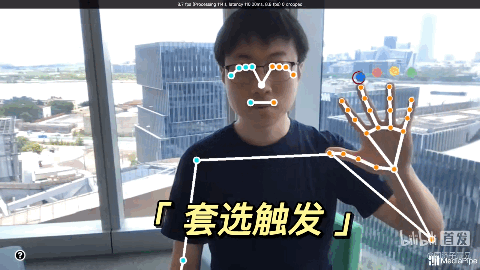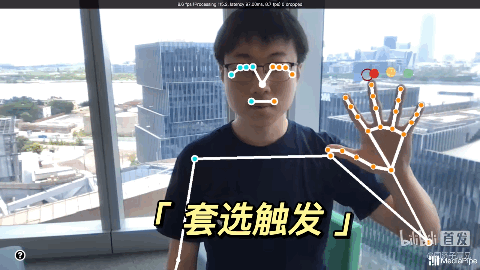
通过Mediapipe,用手势隔空玩游戏。很有钢铁侠操控面板的感觉了!
AI技术,在不同的场合有着不同的应用。而像语音操控、眼神操控这一类技术,直接的受益人就是一些在生活中存在身体缺陷的人。
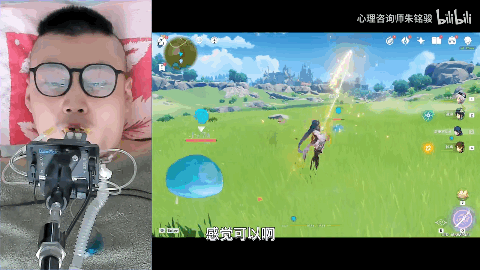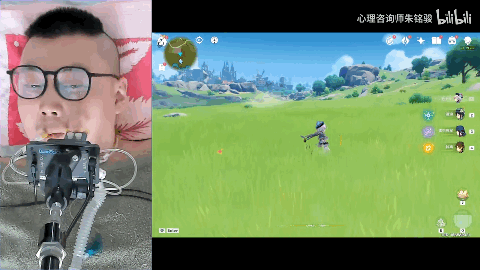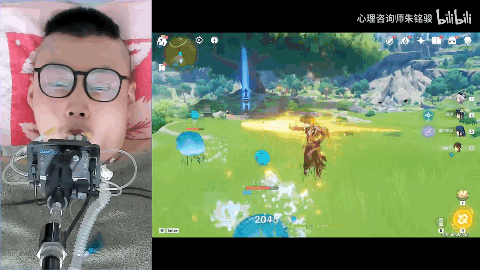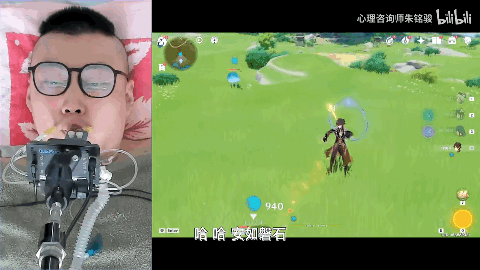
[ 图片来源:哔哩哔哩所有者:心理咨询师朱铭骏 ]
此前便有一位高位截肢的退役消防员小哥在网上分享了他用嘴巴操作手机玩原神的视频,等AI语音玩游戏成熟了,他就可以通过语音更加轻松的在原神的世界游玩。
作者在后期也打算加入“全自动刷本、传送、打怪,领奖励一条龙”的AI操作,到时候我们也将看到一个更加有趣的场景,让我们一起拭目以待。
不懂这些算法的小伙伴们也不用担心,作者目前已经将源码分享到了github上,小伙伴们前往下载安装之后,根据咱们上面说的,改改操作代码,体验一把语音玩原神。
源代码链接:https://github.com/7eu7d7/genshin_voice_play