随着游戏世界变得越来越庞大和复杂,确保它们的可玩性和无错误对开发人员来说变得越来越困难。游戏公司正在寻找包括人工智能在内的新工具,以帮助克服测试其产品所面临的日益严峻的挑战。
电子艺界的一组人工智能研究人员发表的一篇新论文表明,深度强化学习代理可以帮助测试游戏并确保它们是平衡的和可解的。
“对抗性强化学习的程序内容生成,”由EA的研究人员提出的技术,是一种新的办法,解决一些以前的人工智能方法和测试游戏的缺点。
测试大型游戏环境
EA 高级机器学习研究工程师、该论文的第一作者 Linus Gisslén 告诉 TechTalks:“今天的大型游戏可以拥有 1000 多名开发人员,并且经常在 PlayStation、Xbox、移动设备等平台上发布。”“此外,随着开放世界游戏和实时服务的最新趋势,我们看到许多内容必须以我们以前在游戏中从未见过的规模以程序方式生成。所有这些都引入了许多‘移动部件’,所有这些部件都会在我们的游戏中产生错误。”
开发人员目前可以使用两种主要工具来测试他们的游戏:脚本机器人和人类游戏测试员。人类游戏测试员非常擅长发现错误。但是在处理广阔的环境时,它们的速度会大大减慢。他们也会感到无聊和分心,尤其是在一个非常大的游戏世界中。另一方面,脚本机器人速度快且可扩展。但是它们无法与人类测试人员的复杂性相提并论,并且在开放世界游戏等大型环境中表现不佳,在这种环境中,盲目探索不一定是成功的策略。
“我们的目标是使用强化学习 (RL) 作为一种方法,将人类的优势(自学、自适应和好奇)与脚本机器人(快速、廉价和可扩展)相结合,”Gisslén 说。
强化学习是机器学习的一个分支,其中 AI 代理试图采取行动以最大化其环境中的奖励。例如,在游戏中,RL 代理从采取随机动作开始。根据它从环境中获得的奖励或惩罚(生存、失去生命或健康、获得积分、完成关卡等),它制定了一项可产生最佳结果的行动政策。
使用对抗性强化学习测试游戏内容
在过去十年中,人工智能研究实验室已经使用强化学习来掌握复杂的游戏。最近,游戏公司也对在游戏开发生命周期中使用强化学习和其他机器学习技术产生了兴趣。
例如,在游戏测试中,可以训练 RL 代理通过让它在现有内容(地图、关卡等)上玩来学习游戏。一旦代理掌握了游戏,它可以帮助发现新地图中的错误。这种方法的问题在于,强化学习系统经常会在训练期间看到的地图上过度拟合。这意味着它会非常擅长探索这些地图,但在测试新地图方面却很糟糕。
EA 研究人员提出的技术通过“对抗性强化学习”克服了这些限制,这种技术受到生成对抗网络(GAN) 的启发,GAN 是一种深度学习架构,可以让两个神经网络相互对抗以创建和检测合成数据。
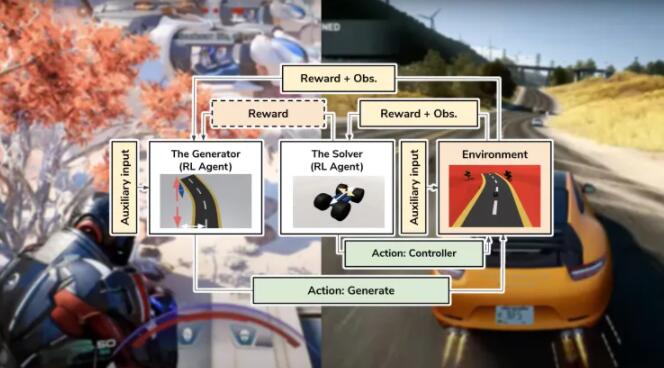
在对抗性强化学习中,两个 RL 代理竞争和协作以创建和测试游戏内容。第一个代理 Generator 使用程序内容生成 (PCG),这是一种自动生成地图和其他游戏元素的技术。第二个代理,即求解器,尝试完成生成器创建的关卡。
两种代理之间存在共生关系。求解器通过采取行动帮助它通过生成的关卡而获得奖励。另一方面,生成器因创建具有挑战性但并非不可能完成求解器的关卡而获得奖励。随着训练的进行,这两个代理相互提供的反馈使他们能够更好地完成各自的任务。
级别的生成以逐步的方式进行。例如,如果对抗性强化学习系统用于平台游戏,则生成器会创建一个游戏块,并在求解器设法到达它后移动到下一个。
“使用对抗性 RL 代理是其他领域的一种经过审查的方法,通常需要使代理充分发挥其潜力,”Gisslén 说。“例如,DeepMind 在让Go 代理与不同版本的自身对战以取得超人类的结果时,就使用了这个版本。我们将其用作在训练中挑战 RL 代理的工具,使其变得更加通用,这意味着它对环境中发生的变化会更加稳健,这在游戏测试中经常出现,其中环境可以在日常。”
渐渐地,生成器将学会创建各种可解的环境,而解算器在测试不同环境时将变得更加通用。
一个强大的游戏测试强化学习系统可能非常有用。例如,许多游戏都有允许玩家创建自己的关卡和环境的工具。与传统机器人相比,经过各种 PCG 生成级别训练的 Solver 代理在测试用户生成内容的可玩性方面效率更高。
对抗性强化学习论文中有趣的细节之一是引入了“辅助输入”。这是一个影响生成器奖励并使游戏开发者能够控制其学习行为的旁道。在论文中,研究人员展示了如何使用辅助输入来控制 AI 系统生成的关卡难度。
EA 的 AI 研究团队将该技术应用于平台和赛车游戏。在平台游戏中,生成器从起点到目标逐渐放置方块。Solver 是玩家,必须从一个块跳到另一个块,直到到达目标。在赛车游戏中,生成器放置赛道的各个部分,求解器将汽车开到终点线。
研究人员表明,通过使用对抗性强化学习系统并调整辅助输入,他们能够在不同级别控制和调整生成的游戏环境。
他们的实验还表明,使用对抗性机器学习训练的求解器比使用固定地图训练的传统游戏测试机器人或 RL 代理更健壮。
将对抗强化学习应用于真实游戏
该论文没有详细解释研究人员用于强化学习系统的架构。那里的少量信息表明,生成器和求解器使用具有 512 个单元的简单的两层神经网络,训练成本应该不会很高。然而,论文中包含的示例游戏非常简单,强化学习系统的架构应该根据目标游戏的环境和动作空间的复杂程度而有所不同。
“我们倾向于采取务实的方法并尽量将培训成本保持在最低水平,因为这对于我们的 QV(质量验证)团队来说是一个可行的投资回报率选择,”Gisslén 说。“我们试图保持每个受过训练的智能体的技能范围只包括一个技能/目标(例如,导航或目标选择),因为具有多个技能/目标的比例非常差,导致模型的训练成本非常高。”
EA 研究总监、论文合著者康拉德·托尔玛 (Konrad Tollmar) 告诉 TechTalks,这项工作仍处于研究阶段。“但我们正在与 EA 的各个游戏工作室合作,探索这是否是满足他们需求的可行方法。总的来说,我真的很乐观地认为 ML 是一种技术,未来将以某种形式或形式成为任何 QV 团队的标准工具,”他说。
研究人员认为,对抗性强化学习代理可以帮助人类测试人员专注于评估无法用自动化系统测试的游戏部分。
“我们的愿景是,我们可以通过从平凡和重复的任务(例如发现玩家可能卡住或跌落地面的错误)转移到更有趣的用例(例如测试游戏平衡、元数据)来释放人类游戏测试员的潜力。游戏和‘乐趣’,”Gisslén 说。“这些是我们在不久的将来不会看到 RL 代理做的事情,但对游戏和游戏制作非常重要,因此我们不想花费人力资源进行基本测试。”
强化学习系统可以成为创建游戏内容的重要组成部分,因为它将使设计师能够在创建环境时评估其环境的可玩性。在论文随附的视频中,研究人员展示了关卡设计师如何在为平台游戏放置块时实时从 RL 代理获得帮助。
Tollmar 认为,最终,这个和其他人工智能系统可以成为内容和资产创建的重要组成部分。
“这项技术仍然是新的,在完全起飞之前,我们在生产管道、游戏引擎、内部专业知识等方面还有很多工作要做,”他说。“然而,根据目前的研究,当 AI/ML 成为整个游戏行业使用的主流技术时,EA 将做好准备。”
随着该领域研究的不断推进,人工智能最终可以在游戏开发和游戏体验的其他部分发挥更重要的作用。
“我认为随着技术的成熟以及游戏公司的接受度和专业知识的增长,这不仅将用于测试中,而且还将作为游戏 AI,无论是协作、对手还是 NPC 游戏 AI,”托尔玛说。“当然,也可以将训练有素的测试代理想象成您可以与之对抗或合作的已发布游戏中的角色。”