原文作者:SuchithraRajendran博士和Janae Bradley
近期,BMC Veterinary Research 上发表了一项机器学习研究的最新结果,该研究可用于预测动物将在一个收容所呆的时间,以尽量减少它们停留的时间和被安乐死的机会,决定哪里的收容所是最适合收养它们的。Suchi Rajendran博士和Janae Bradley与我们分享了更多有关这项工作的精彩细节。

我们之中有多少人喜欢动物,又有多少人把宠物当成家庭的一部分呢?如果我告诉你,每年进入救助站的动物数量高达600万~800万,其中有300万~400万只(即50%的进站动物)被安乐死,你会怎么想?更令人心痛的是,每年有10%~25%的动物是因为收容所空间不足而被处死的。
家养动物数量过多的问题持续增加,收容所面临的增高收养率挑战也日益严峻。虽然动物收容所提供了减免领养费和在领养前对动物进行消毒等激励措施,但生活在收容所的动物仍只有四分之一被领养。
这些惊人的统计数据促使我们调查动物在收容所的停留时间,以及影响动物收养率的因素。本研究的首要目标是利用这些因素进行预测,尽量减少动物在收容所的停留时间,从而减少因空间不足而被安乐死的动物数量。要实现这个目标必须进行几个步骤,如:通过文献检索了解相关因素,从数据库和动物收容所收集数据,并借助机器学习算法用这些数据预测动物在收容所的停留时间。

为了了解动物在收容所停留时间的影响因素,我们进行了全面的文献综述,发现有几个因素会影响停留时间的长短,包括动物的颜色、性别、品种、动物类型和年龄。为了利用这些因素对停留时间进行预测,我们使用机器学习算法和预测分析进行了评估。
机器学习就是利用训练经验,让计算机自己编程学习和改进的能力。开发的系统需要分析大数据,快速提供准确和可重复的结果,并能够被应用于新数据。通过从所需输入输出数据的例子中学习,可以训练系统做出准确的预测。换句话说,我们希望让计算机利用一个停留时间已知的标签数据集来进行学习。下一步就是从全国各地的数据库和动物收容所中获取这些数据。
从数据库和动物收容所收集的数据包括动物类型、收容和离开的日期、性别、颜色、品种、收容和离开的状态(动物进入和离开收容所的行为表现)等信息。这些数据集包括主要来自美国南部和西南部各州的信息。停留时间的类别分为“短时间”、“中等时间”、“长时间“和“超长时间”(安乐死)。 一旦收集并整理好数据,就可以将其输入到机器学习算法中。
有许多不同类型的算法可以用于数据集上进行预测,困难的是确定哪种算法在给定的数据集上表现最好,因为模型的性能取决于应用。本研究中使用了简单的分类算法,如逻辑回归、人工神经网络、梯度提升和随机森林。
结果表明,对于该数据集,梯度提升算法开发的预测模型最为成熟,其次是随机森林算法。在所有类别的住院时间上,逻辑回归算法的性能指标似乎都是最差的。有趣的是,当预测“超长停留时间”或安乐死时,梯度提升和随机森林算法表现良好,准确率约为70-80%。
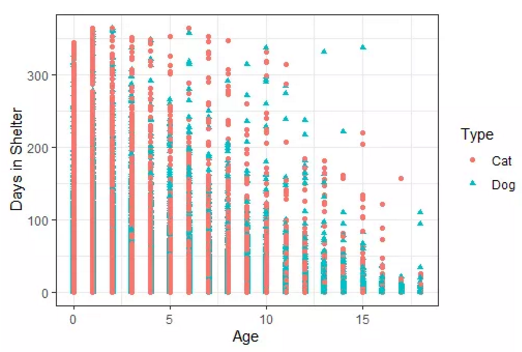 猫狗年龄与其在收容所停留天数的比较
猫狗年龄与其在收容所停留天数的比较从上述探索性数据的结果来看,我们发现,随着年龄的增长,狗在收容所的停留天数会减少。这是在意料之外的,因为预计年龄较小的狗和幼犬在收容所的停留天数会较少。这一观察结果可能是由于年龄较小的狗有更多的数据点。
研究的另一个有趣的结果是每种机器学习算法得出的主要影响特征或因素。结果显示,年龄(成年狗、老年狗和幼狗)、大小(大和小)和颜色(多色)对停留时间有重大影响。
在未来的研究中,我们将采取规范性分析方法,目的不仅局限于提高动物收容所中宠物的收养率,而且还要确定最佳的动物收容所位置,让动物在收容所中停留的时间最短且最有可能被收养。
BMC Veterinary Research
doi:10.1186/s12917-020-02728-2