来源:机器之心
机器之心报道
机器之心编辑部
这次,Transformer 参与了舞蹈生成任务。
在艺术领域,AI 有着各式各样的应用,如 AI 生成音乐、AI 绘画。
跳舞,也是 AI 努力学习的一种能力。
此前,以音乐的风格、节奏和旋律作为控制信号来生成 3D 舞蹈动作的 DaceNet 曾红极一时。
如今,DanceNet 迎来了新的挑战者——来自谷歌的最新研究 AI Choreographer:给定一段 2 秒的指导动作,AI 模型可以按照音乐节奏生成一长段自然的舞蹈动作。
生成的舞蹈效果是这样的(遗憾的是动图没有声音):
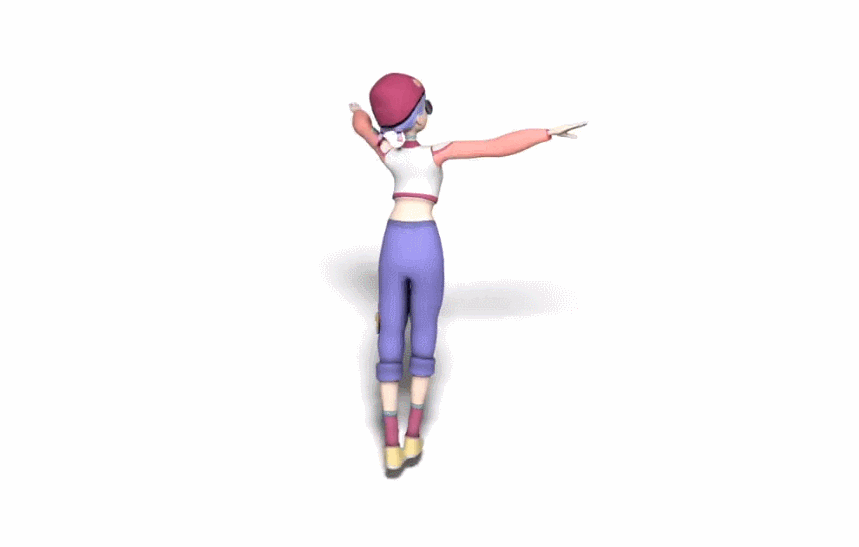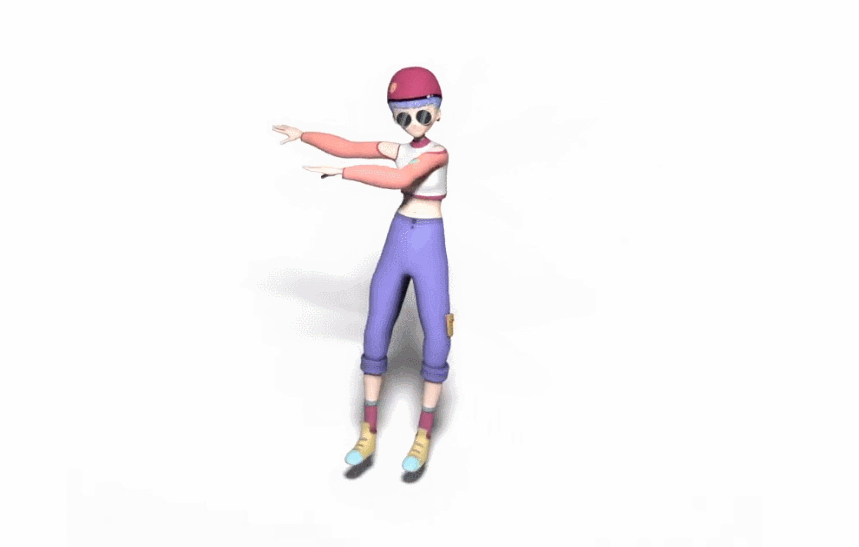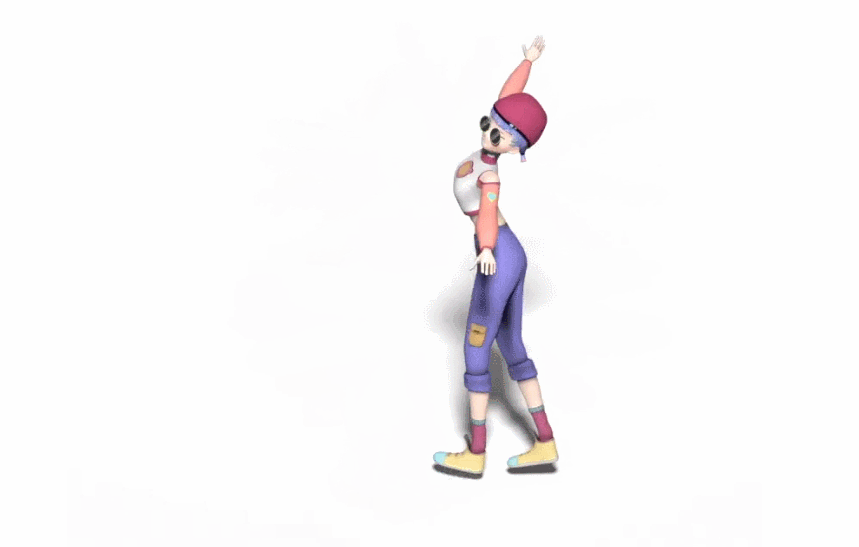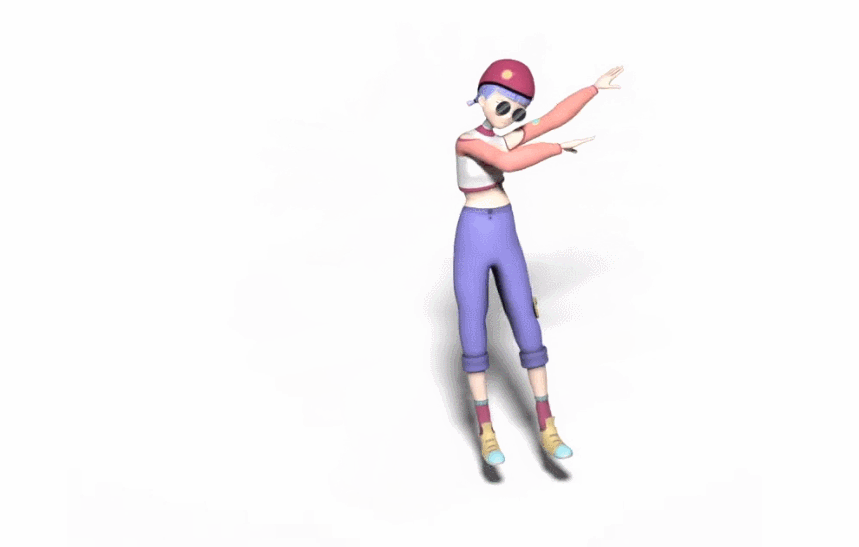
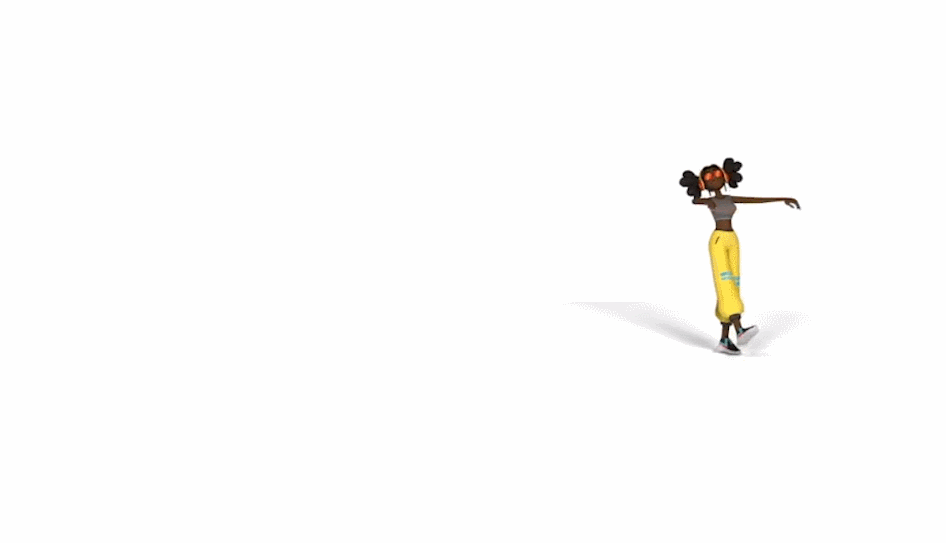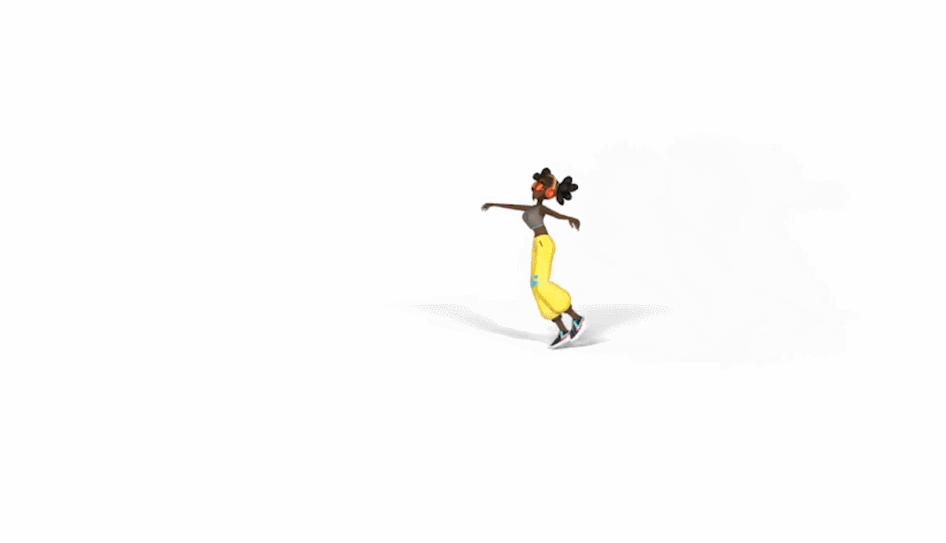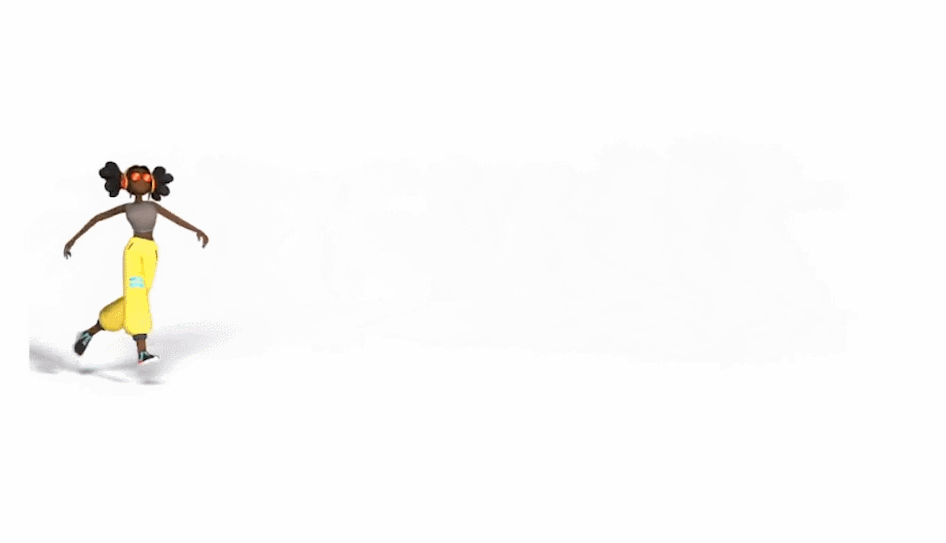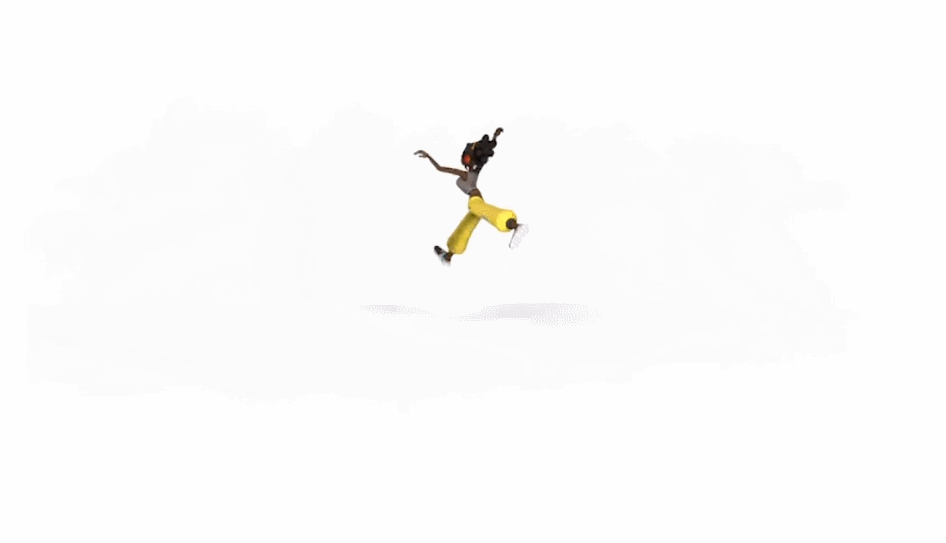
而和 DanceNet 这些同类研究相比,谷歌新方法的效果更为明显。左边两种方法生成的舞蹈动作像「抽风」,该新方法则更加流畅自然:

值得注意的是,这还是一个基于Transformer 的模型。

论文地址:https://arxiv.org/pdf/2101.08779v1.pdf
项目地址:https://google.github.io/aichoreographer/
下面让我们看下论文细节:
通过编排与音乐节拍一致的动作模式来跳舞是人类的一项基本能力。舞蹈是所有文化中的通用语言,如今,许多人在多媒体平台上通过舞蹈来表现自己。在 YouTube 上最受欢迎的视频是以舞蹈为主的音乐视频,例如 Baby Shark Dance、江南 Style,在互联网信息传播中,舞蹈成为强大的传播工具。
然而,舞蹈是一种艺术形式,即使是人类,也需要专业培训才能使舞蹈演员掌握丰富的舞蹈动作曲目,创造出富有表现力的舞蹈编排。从计算方面来讲更具有挑战性,因为该任务需要有能力生成一个连续的高运动学复杂度动作,捕捉与伴奏音乐的非线性关系。
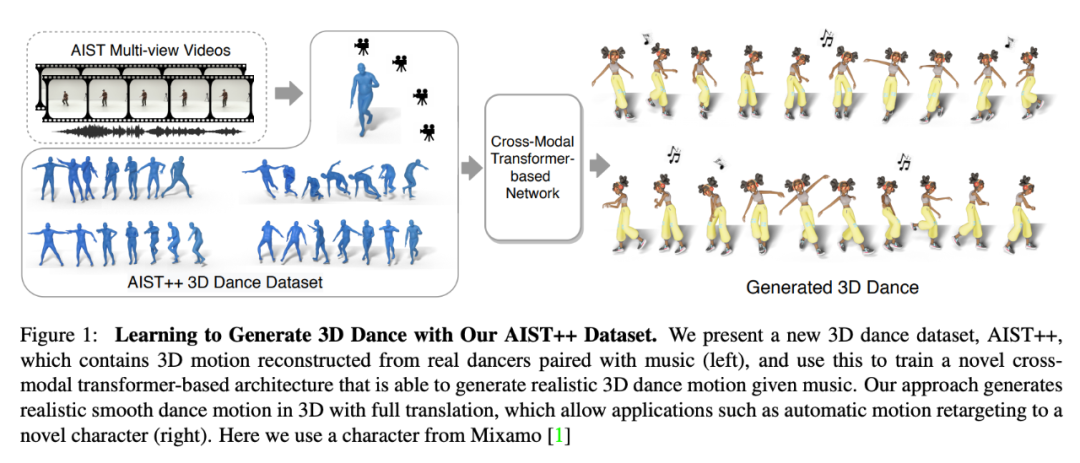
在这项研究中,来自南加州大学、谷歌研究院、加州大学伯克利分校的研究者提出了一个基于 transformer 的跨模态学习架构和一个新的 3D 舞蹈动作数据集 AIST++,该数据集用来训练一个生成 3D 舞蹈动作的模型。
具体来说,给定一段音乐和一个短的(2 秒)种子动作(seed motion),本文模型能够生成一个长序列的逼真 3D 舞蹈动作。该模型有效地学习了音乐动作的相关性,并且可以生成不同输入音乐的舞蹈序列。研究者将舞蹈表示为一个由关节旋转和全局平移组成的 3D 动作序列,这使得输出可以很容易地迁移至动作重定向等应用,具体流程如下图 1 所示:
在学习框架方面,该研究提出了一种新的基于 transformer 的跨模态架构来生成基于音乐的 3D 动作。该架构建立在已被证明对长序列生成特别有效的基于注意力的网络 [15, 62, 3, 71]上,并从视觉和语言的跨模态文献 [71] 中获得灵感,设计了一个使用三个 transformer 的框架,分别用于音频序列表示、动作表示和跨模态音频 - 动作表示。其中动作和音频 transformer 对输入序列进行编码,而跨模态 transformer 学习这两种模态之间的相关性,并生成未来的动作序列。
该研究精心设计的新型跨模态 transformer 具有自回归特性,但需要全注意力(full-attention)和 future-N 监督,这对于防止 3D 运动在多次迭代后冻结或漂移非常关键,正如先前关于 3D 运动生成所述[4,3]。由此生成模型为不同的音乐生成不同的舞蹈序列,同时生成长时间的逼真动作,在进行推理时不受漂移冻结的影响。
AIST++ 数据集
为了训练模型,该研究还创建了一个新的数据集:AIST++。该数据集在 AIST(多视角舞蹈视频库) [78]基础上进行构建。研究者利用多视角信息从数据中恢复可靠的 3D 动作。注意,虽然这个数据集具有多视角照片,但相机并未校准,这使得 3D 重建非常具有挑战性。
AIST++ 数据集包含高达 110 万帧伴有音乐的 3D 舞蹈动作,据了解,这是此类数据集中最大的一个。AIST++ 还跨越了 10 种音乐类型、30 个主题和 9 个视频序列,并具有恢复的相机内在特性,这对于其他人体和动作研究具有很大的潜力。
数据集地址:https://google.github.io/aistplusplus_dataset/
该研究创建的 AIST++ 是一个大规模 3D 舞蹈动作数据集,包含大量伴随音乐的 3D 舞蹈动作。其中每一帧都具备以下额外标注:
9 种视角,包括摄像机的内外参数;
17 种 COCO 格式的人类关节位置,包含 2D 和 3D 形式;
24 个 SMPL 姿势参数,以及全局扩展和平移。
下表 1 对比了 AIST++ 和其他 3D 动作与舞蹈数据集,AIST++ 对于现有的 3D 动作数据集是一种补充。

此外,AIST++ 数据集包含 10 个舞种:Old School(Break、Pop、Lock 和 Waack)和 New School(Middle Hip-hop、LA-style Hip-hop、House、Krump、Street Jazz 和 Ballet Jazz),参见下图 3:

基于音乐的3D 舞蹈生成
问题描述:给定一个 2 秒的动作种子示例 X = (x_1, . . . , x_T) 和音乐序列 Y = (y_1, . . . , y_T'),生成时间步 T + 1 到 T' 期间的未来动作序列 X'= (x_T+1, . . . , x_T'),T' >> T。
跨模态动作生成 Transformer
该研究提出一种基于 Transformer 的网络架构,它可以学习音乐 - 动作关联,生成不凝滞的逼真动作序列。架构图参见下图 2:
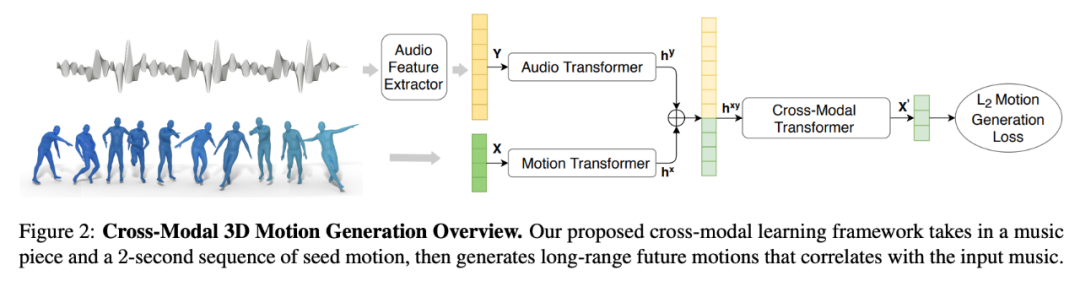
该模型具备三个transformer:
动作 transformer f_mot(X):将动作特征 X 转换为动作嵌入 h^x_1:T;
音频 transformer f_audio(Y):将音频特征 Y 转换为音频嵌入 h^y_1:T';
跨模态 transformer f_cross(h^xy_1:T +T'):学习动作和音频两个模态之间的对应,并生成未来动作 X'。
为了更好地学习两个模态之间的关联,该研究使用了一个深度为 12 层的跨模态 transformer。研究者发现,跨模态 transformer 的深度越大,模型对两种模态的关注越多(参见下图 6)。

实验
定量评估
研究者报告了该方法与两种基线方法在 AIST++ 测试集上的定量评估结果,见下表 2:
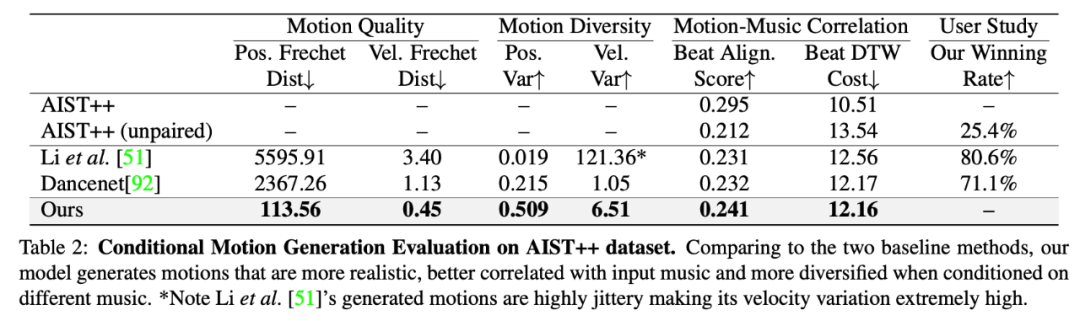
动作质量:从上表中可以看出,该方法生成的动作序列关节和速度分布更接近真值动作。
动作多样性:表 2 展示了,相比基线方法,该研究提出的方法能够生成更多样的舞蹈动作。控制变量研究结果表明,网络设计,尤其跨模态 transformer,是带来这一差异的主要原因。研究者将该方法生成的多样化舞蹈动作进行了可视化,参见下图 7:

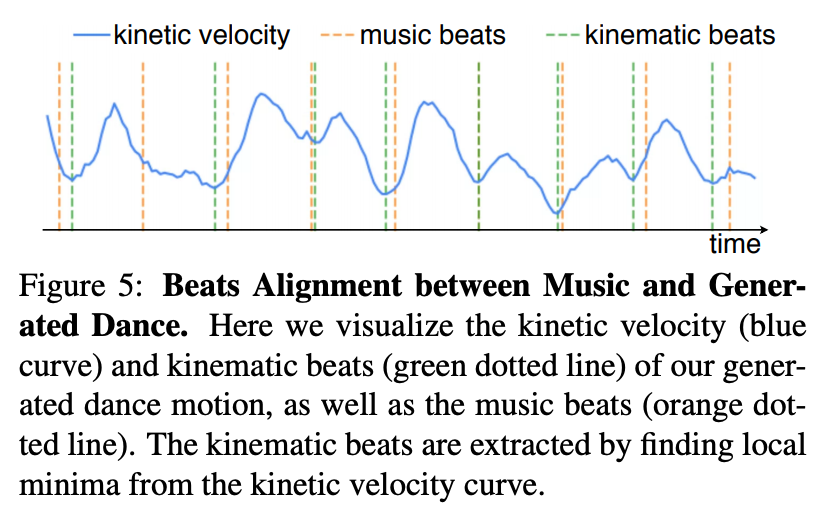
动作- 音乐关联:从表 2 中还可以看出,该方法生成的动作与输入音乐的关联性更强。下图 5 中的示例展示了生成动作的运动节拍与音乐节拍能够实现很好地匹配。
但是,在与真实数据进行对比时,这三种方法都有很大的改进空间。这表明,音乐动作关联仍然是一个极具挑战性的问题。
控制变量研究
跨模态 Transformer:该论文利用三种不同设置研究跨模态 Transformer 的功能:1)14 层动作 transformer;2)13 层动作 / 音频 transformer 和 1 层跨模态 Transformer;3)2 层动作 / 音频 transformer 和 12 层跨模态 Transformer。
下表 3 表明跨模态 Transformer 对于生成与输入音乐关联性强的动作至关重要。
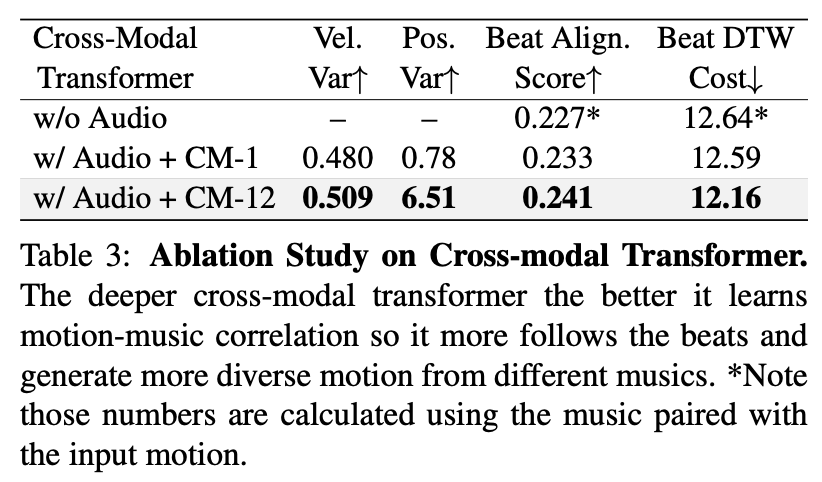
如图 6 所示,更深的跨模态 Transformer 能够更加关注输入音乐,从而带来更好的音乐 - 动作关联度。

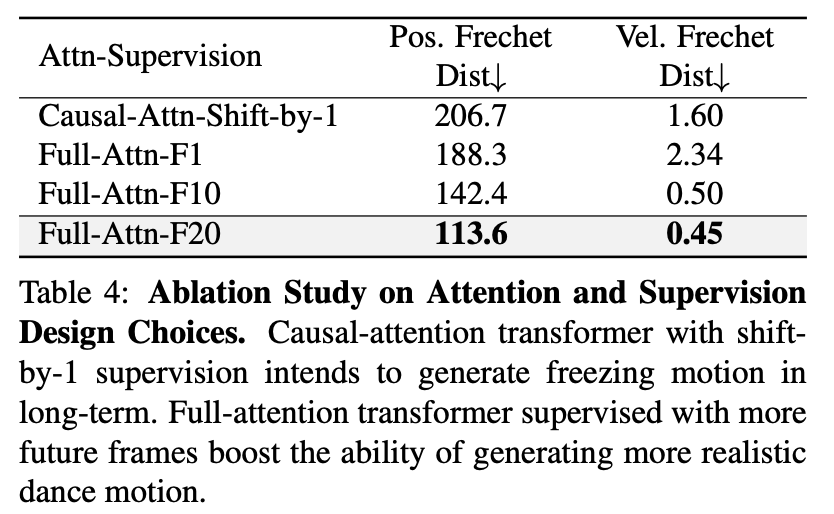
因果注意力或完全注意力Transformer:研究者还探索了完全注意力机制和 future-N 监督机制的效果。从下表 4 中可以看出,在使用因果注意力机制执行 20 秒长程生成时,生成动作和真值动作的分布差异很大。对于 future-1 监督设置下的完全注意力机制而言,长程生成期间的结果会出现快速漂移,而在 future-10 或 future-20 监督设置下,模型可以生成高质量的长程动作。
AAAI2021线上分享 |BERT模型蒸馏技术,阿里云有新方法
在阿里巴巴等机构合作、被AAAI 2021接收的论文《Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation 》中,研究者们提出了一种跨域自动数据增强方法来为数据稀缺领域进行扩充,并在多个不同的任务上显著优于最新的基准。
1月27日20:00,论文共同一作、阿里云高级算法专家邱明辉为大家详细解读此研究。
添加机器之心小助手(syncedai5),备注「AAAI」,进群一起看直播。