来源:机器之心
编辑:Panda
抢射手?抢中单位?「绝悟」在打王者荣耀时是如何选英雄的?
腾讯 AI Lab 开发的 AI 智能体「绝悟」已让王者峡谷不再只是人类召唤师的竞技场,而且这个 AI 战队在上月底进化成了「完全体」。在一局完整的比赛中,英雄选择阶段是至关重要的(比如五射手或五法师阵容会有官方劝退)。
近日,腾讯 AI Lab 和上海交通大学发布的一篇论文介绍了绝悟的英雄选择策略:JueWuDraft。别的不敢说,有一点可以肯定:人工智能不会乱抢英雄。
玩 MOBA 游戏,选英雄很关键,因为这决定了双方队伍的阵容,会直接影响战绩、胜负等最终结果。之前最佳的选英雄方法通常没有考虑以下因素:1)英雄池扩大时选英雄的效率,2)MOBA 游戏 5v5 的多轮竞赛机制,即两支队伍比赛 N 局,获胜次数更多的队伍获胜(best-of-N),而在这一系列比赛中,每个英雄只能被选择一次。
腾讯 AI Lab 和上海交通大学合作的这篇论文将阵容选择过程描述成了一个多轮组合博弈过程,并提出了一种全新的阵容选择算法 JueWuDraft,该算法基于神经网络和蒙特卡洛树搜索。具体来说,作者设计了一种长期的价值估计机制,可以更好地应对 best-of-N 比赛的选英雄情况。研究者在大热 MOBA 手游《王者荣耀》中检验了该方法,结果表明:相较于其它当前前沿的方法,JueWuDraft 的实用性和有效性都更胜一筹。
「选英雄」的重要性
自 AlphaGo 和 AlphaZero 在棋盘类游戏上击败了人类职业玩家以来,游戏人工智能(Game AI)一直备受关注。另外,我们也见证了 AI 智能体在其它游戏类型上的成功,包括 Atari 系列游戏和夺旗游戏等第一人称射击游戏(FPS)、《任天堂明星大乱斗》等视频游戏、扑克等纸牌游戏。尽管如此,相比于复杂的实时策略游戏(RTS),这些游戏要简单得多,因为 RTS 游戏更能体现真实世界的本质。因此,近来的研究者更加关注 RTS 游戏,比如《Dota 2》、《星际争霸》和《王者荣耀》。
RTS 游戏有一个子类别是多人在线战术竞技游戏(MOBA),这是当今最受欢迎的一类电子竞技游戏。MOBA 游戏的游戏机制涉及到多智能体竞争和协作、不完美信息、复杂动作控制、巨大的状态 - 动作空间。也因此,MOBA 游戏被视为 AI 研究的首选测试平台。MOBA 的标准游戏模式是 5v5,即两支各包含 5 位玩家的队伍互相对抗。最终目标是摧毁对方队伍的基地 / 水晶 / 堡垒。每位玩家都会控制单个游戏角色,通常称为「英雄」,并与其他队友协作攻击对方的英雄、小兵、炮塔和中立生物,同时保护己方的单位。
一局 MOBA 游戏通常包含两个阶段:1)匹配阶段,在此期间,两支队伍的 10 位玩家从英雄池挑选英雄,这个过程也被称为「英雄选择」或「选英雄」;2)比赛阶段,两支队伍开始战斗,直至游戏结束。下图是《王者荣耀》英雄阵容选择阶段的游戏截图。在挑选英雄时,两支队伍会轮流选择,直到每位玩家都各自选择一个英雄。最终选出的英雄阵容会直接影响之后的游戏策略和最终比赛结果。因此,为了构建能完整地玩 MOBA 游戏的 AI 系统,选英雄阶段非常重要而且也是必需的。
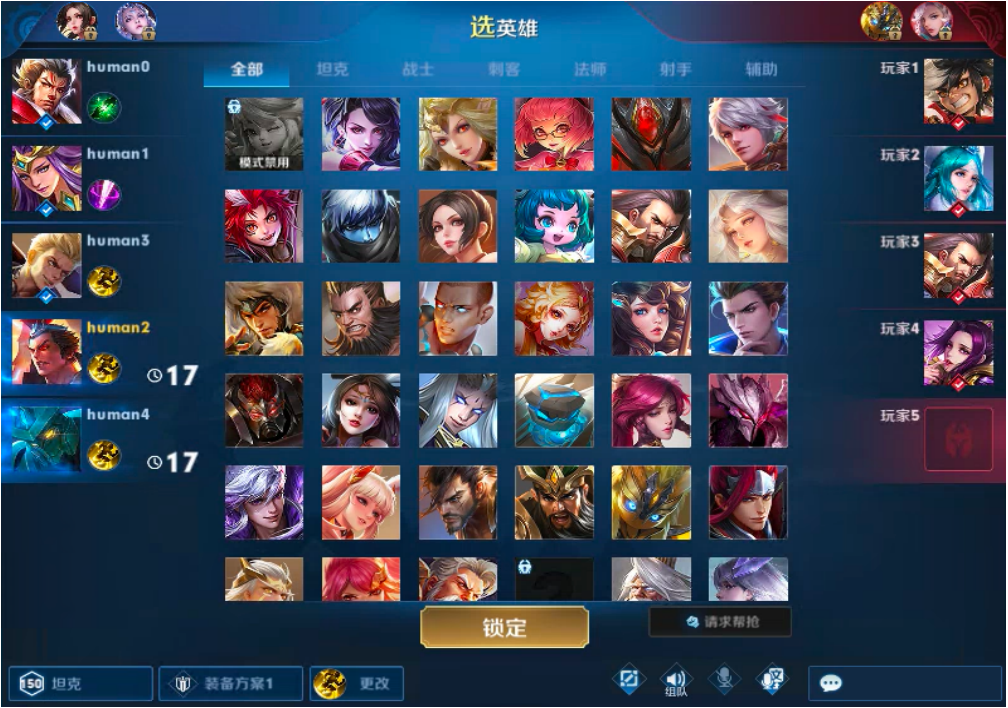 图 1:《王者荣耀》选英雄界面截图
图 1:《王者荣耀》选英雄界面截图为了确定两支队伍的胜败,常用的评估规则是 best-of-N,其中 N 可为奇数 1、3、5,意思是执行 N 局比赛,直到某个队伍赢得 (N+1)/2 局,比如三局两胜或五局三胜。
在 MOBA 游戏中,每个英雄都有独特的技能和能力。每支队伍 5 个英雄的技能和能力综合起来即为该团队的整体实力。另外,英雄彼此之间还存在复杂的压制和互补关系。举个例子,在《Dota 2》中,敌法师的技能能削减敌方英雄的魔法值,因此它「天克」美杜莎,因为美杜莎的持续作战能力严重依赖魔法量。再举另一个例子,在《王者荣耀》中,明世隐能提升所有己方英雄的普攻伤害,使其为射手英雄后羿提供强力辅助。因此,为了赢得比赛,玩家选英雄时需要谨慎考虑如何增强队友英雄的能力或补充其弱点,以及如何克制对方英雄。
在《王者荣耀》和《Dota 2》等 MOBA 游戏中,选英雄阶段可选英雄的数量可能超过 100 个。比如,最新版的《王者荣耀》已有 102 个英雄。因此,可能的英雄阵容数量可达 5.37×10^¹⁵(
),即从包含 102 个英雄的英雄池中选出 10 个英雄,然后从这 10 个中选出 5 个)。由于英雄之间存在复杂的关系,阵容也有非常多的可能性,选择配合队友和克制敌方的英雄对人类玩家来说也颇具挑战性。
在 MOBA 英雄选择方面,当前最佳方法来自 OpenAI Five 和 DraftArtist。OpenAI Five 是一个玩《Dota 2》的 AI 程序,它使用 Minimax 算法来选择英雄,因为它仅支持 17 个英雄。但是,Minimax 会构建一个完整的搜索树,这个搜索树由每位玩家交替的可能选择构成,这使其在计算上难以扩展用于大型英雄池,比如 100 个英雄。DraftArtist 使用了蒙特卡洛树搜索(MCTS),即通过模拟阵容完成前可能的后续选取过程来估计每次选取的价值。但是,它只考虑单次竞赛,即 best-of-1(一局定胜负),这可能导致阵容选择结果不是最优。此外,MCTS 模拟采用随机 roll-out(推演)来获得奖励,这种方法的效率很低。
腾讯 AI Lab 和上海交通大学的这篇论文将 MOBA 游戏选英雄的过程描述成了一个双玩家使用完美信息的零和博弈问题。每个玩家的目标都是最大化己方队伍相对于敌方队伍的胜率(敌我队伍各有五个英雄);另一个条件是英雄池中每个英雄都只能被同一个队伍选择一次。
为了解决这个问题,该论文提出了组合使用蒙特卡洛树搜索(MCTS)和神经网络的方法。具体来说是将 MCTS 与策略和价值网络组合起来,其中价值网络的作用是直接预测当前状态的价值来获得奖励,而不是执行效率低下的随机 roll-out。在国际象棋和围棋等棋盘游戏中,竞赛的胜者由最终的状态决定,而选英雄过程却不一样,其终点并非一局 MOBA 比赛的终点。因此,我们不能直接获取比赛结果。为了解决这个问题,作者构建了一个神经预测器,用以预测特定阵容的胜率。这个最终状态的胜率可用作预测 MCTS 的反向传播和训练价值网络的奖励。
此外,根据 best-of-N 规则,为当前一局比赛选择的英雄会影响后续几局的选择。针对这个特点,作者提出将选英雄过程描述为一个多轮组合博弈过程,并设计了一套长期价值机制。这样得到的选英雄策略能更长远地考虑当前对局和后续对局。
总体而言,该研究的贡献如下:
为 MOAB 游戏提出了一种名为 JueWuDraft 的选英雄方法,该方法利用了神经网络和蒙特卡洛树搜索。具体来说是将 MCTS 与策略和价值网络组合到了一起,其中价值网络是用于评估当前状态的价值,策略网络则是为下个英雄选择执行动作采样。
将 best-of-N 选英雄问题描述成了一个多轮组合博弈问题,其中每一局游戏都有一个对最终阵容的预测胜率。为了适应这样的 best-of-N 选英雄问题,作者设计了一套长期价值机制。这使得对当前状态的价值估计会考虑到后续对局。
作者在单局和多局游戏上执行广泛的实验验证,结果表明:相较于其它当前最佳方法,JueWuDraft 能取得更优的表现。
相关工作
在 MOBA 游戏选英雄问题上,之前的方法主要分为以下四类:
1. 根据该游戏过去的英雄出场率进行选择
2. 根据该游戏之前的英雄胜率进行选择
3. Minimax 算法
4. 蒙特卡洛树搜索
绝悟用这个方法选英雄
问题描述
如前所述,在 MOBA 游戏中,选英雄过程是非常重要的,尤其是在复杂的游戏比赛中。在正式的 MOBA 比赛中,在确定获胜者方面,常用的策略是 best-of-N 多局格式,其中 N 是一个奇数,通常是 best-of-3 或 best-of-5,即三局两胜制或五局三胜制。举个例子,王者荣耀职业联赛(KPL)的比赛形式总是包含多局比赛。其中两支战队会进行多局比赛,直到某支战队赢得其中 (N+1)/2 局比赛。此外,在多局比赛中,KPL 不允许玩家选择己方战队之前几局已经选择过的英雄。这意味着,为了赢得多局比赛的最终胜利,在选择英雄时,既要考虑当前一局比赛,还需要考虑后续几局比赛。
基于这些考虑,除了单独考虑每一局的英雄选择,这篇论文还将全场比赛 G 定义成了一个双玩家零和完美信息博弈问题,其中具有重复的子结构。一场比赛考虑的元素包括玩家数、选择顺序、游戏状态等,详情请见原论文。另需说明该论文未考虑英雄禁选的情况。
使用神经网络和树搜索学习在 MOBA 游戏中选英雄
整体训练框架图 2 展示了 JueWuDraft 的整体训练框架。为了提升训练效率,作者将该框架分散到了多个 CPU 和 GPU 服务器上进行处理。整体而言,该框架包含 4 个模块:数据采样器、样本池、神经网络训练器和模型池。
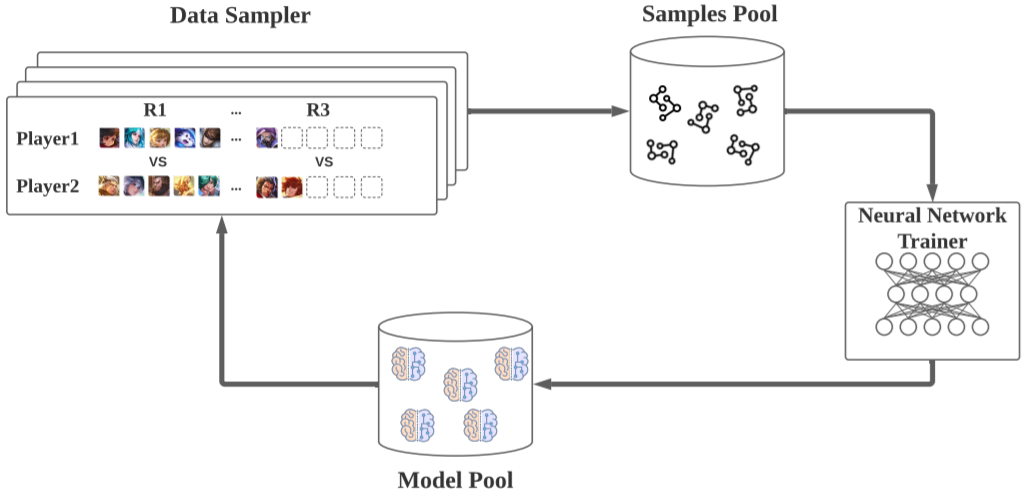
图2:整体训练框架
搭配深度神经网络的并行 MCTS:该框架使用的搜索算法是多项式置信度上限树。为了提升数据采用的速度和充分利用计算资源,对树的搜索是并行执行的。总体而言,PUCT 搜索树是按四个步骤迭代式构建的:选择、评估、扩展和反向传播。图 3 展示了该过程。
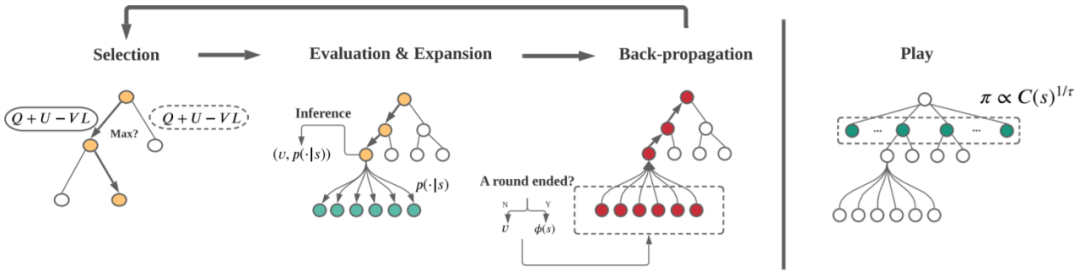
图 3:用于英雄选择过程的 MCTS 每次模拟都分四步:选择、评估、扩展和向后传播。搜索完成后,返回概率 π(其正比于对每个节点的访问次数 C(s))。
策略和价值网络的训练深度神经网络在评估未曾见过的状态的价值方面具有很强的泛化能力,因此也是 JueWuDraft 的重要组成部分,它既可以提供当前价值的稳定参考,也能提供主要动作。另外,这个神经网络还能节省搜索和构建树的时间;相对而言,传统 MCTS 算法会采样到游戏结束,因此会在 rollout 上花很多时间。因此,训练网络的方式很关键。这篇论文提出的网络能在单一框架内输出价值和预言(oracle)策略。
长期价值传播正如前面介绍的,在多局比赛中,早期比赛对局的每次英雄选择都会影响后期对局的选择。另外,将所有相关对局的结果汇总起来预测当前步骤的价值也是很直观的做法。长期价值传播的情况有两种:
MCTS 中的反向传播步骤
价值网络的目标(target)标签
图 4 展示了一场三对局比赛的示例,其中说明了价值网络中上述两种价值传播方式。
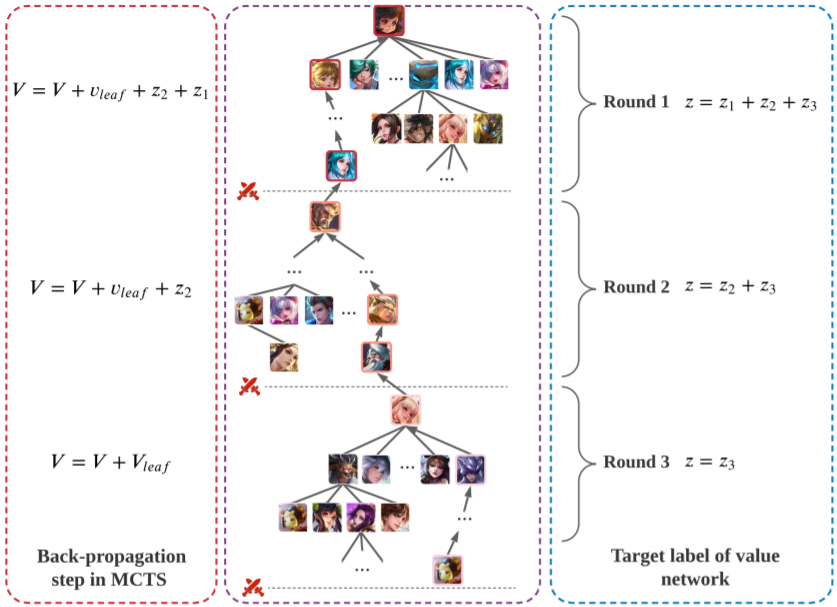
图4:价值传播
网络结构和状态重构:为了以更高效的方式训练策略和价值网络,需要对状态进行重构。如图 5 所示,重构的状态向量主要包含三部分。一是当前英雄选择部分,即当前局的英雄选择,这对当前局的胜率有主要影响。该向量的中间部分是历史的英雄选择信息。最后一部分是关系信息(比如当前对局由哪方先选)。
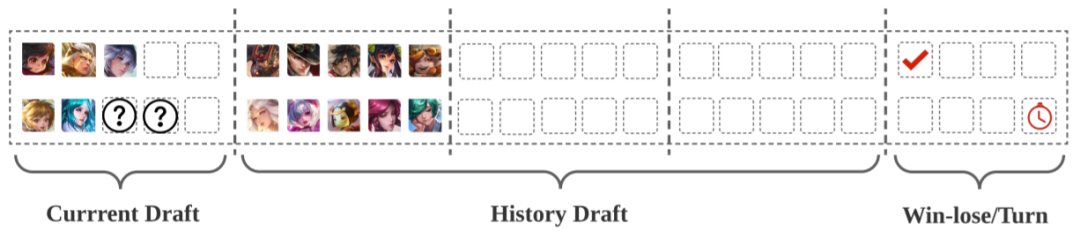
图5:状态向量的配置
如图 6(b) 所示,策略和价值网络使用了一个简单的 3 层全连接神经网络。其以图 5 所示的状态向量为输入,输出则是两个头(head):一个带 softmax 函数的全连接层(策略头,其输出每个动作的概率);一个带 tanh 函数的全连接层(价值头,输出当前状态的价值)。
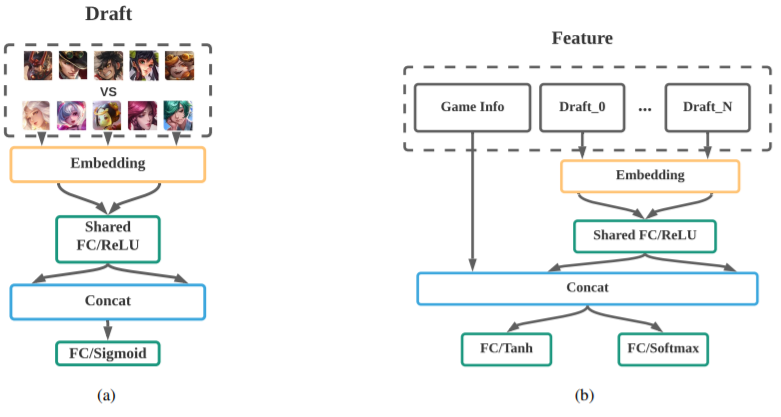
图6:网络架构:(a) 是胜率预测器,(b) 是策略和价值网络
胜率预测器
在选择英雄阶段,只能得到阵容信息,胜负信息是未知的。作者采用了胜率预测器来预测阵容的胜率并将其作为奖励函数。
训练这个胜率预测器所使用的比赛数据集包含阵容和胜负信息。每个英雄都各有一个范围在 [0, N_classes−1] 之间的索引。输入特征由全部 10 个已选择英雄的索引表示。
图 6(a) 给出了胜率预测器的网络架构,这是一个简单的 3 层神经网络,其输出层连接着一个 sigmoid 激活函数。
实验
在实验中,JueWuDraft 总体而言优于其它策略,该算法的有效性和高效性也得到了体现。
具体来说,JueWuDraft 与这三种策略进行了比较:
DraftArtist,使用了单纯的 MCTS,没有策略和价值网络。该策略不会考虑后续对局的情况。
最高胜率(HWR)策略,基于统计数据选择剩余英雄池中胜率最高的英雄。
随机策略(RD),在剩余英雄池中随机挑选一个英雄。
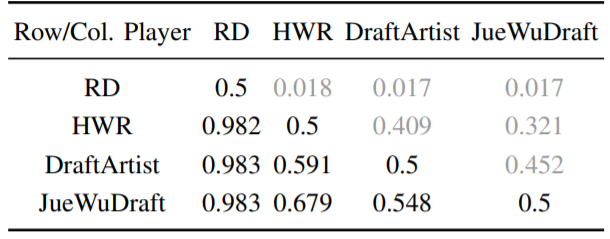
表 1:在 AI 数据集的单局比赛中(各行玩家对抗各列玩家),每一对策略中各行玩家的预测胜率。
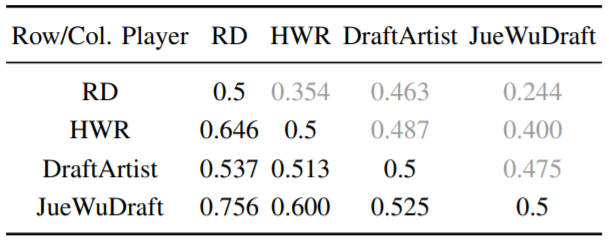
表4:在人类数据集的单局比赛中,每一对策略中各行玩家的预测胜率。
下面说明一个具体的模拟案例,其中上场玩家是 JueWuDraft 与 HWR,如图 10 所示。JueWuDraft 在三局比赛中的预测胜率分别为 56.3%、71.8%、65.1%。其中第二局和第三局中 JueWuDraft 的胜率比第一局更高。具体来说,在第一局中,JueWuDraft 先手选择了成吉思汗而不是平均胜率最高的刘备,尽管首先选择刘备可能会在第一局得到更高的胜率。这说明 JueWuDraft 的贪心策略没有 HWR 那么高,而是会长线考虑,兼顾后面的对局。

图 10:JueWuDraft 对抗 HWR 的一次具体模拟结果,其中 JueWuDraft 先手选择。
研究局限和展望未来
该研究还存在两方面的局限,有待进一步探索和延伸。
第一,该研究还没考虑英雄禁选过程,这也非常重要,通常与选英雄过程合称「Ban/Pick」。
第二,训练数据集是从强化学习训练比赛或人类比赛收集的,尽管这套 AI 系统的目标是击败人类玩家,但训练出的智能体与人类玩家的胜率差距还很明显。而这里设计的胜率预测器还没有充分考虑这一差距。
研究者希望能在这两方面为 JueWuDraft 带来进一步突破。
论文链接:https://arxiv.org/abs/2012.10171
模型调参与算法优化技巧实战
12月29日20:00,百度高级研发工程师现身说法,带来基于全功能AI开发平台BML的算法优化技巧分享,还有现场调参实战与直播Q&A,学练加持,一小时密集输出独家技术干货!
平台能力:全功能AI开发平台BML技术解析
实战演练:模型开发与调参技巧分享
部署应用:服务器端部署流程演示
扫码进群听课,还有机会赢取100元京东卡、《智能经济》实体书、限量百度鼠标垫多重好奖!