来源:机器之心
编辑:魔王、维度
架构变化、训练方法和扩展策略是影响模型性能的不可或缺的重要因素,而当前的研究只侧重架构的变化。谷歌大脑和 UC 伯克利的一项最新研究重新审视了 ResNet 架构,发现对于提升模型性能而言,改进训练和扩展策略或许比架构变化更重要。他们提出了 ResNet 的变体架构 ResNet-RS,其使用的内存不仅更少,在 TPU 和 GPU 上的训练速度也数倍于 EfficientNet。
视觉模型的性能是架构、训练方法和扩展策略的综合结果。但是,研究往往只强调架构的变化。新架构是促成诸多进展的基础,但与新架构同时出现的通常还有训练方法和超参数变化——一些关键但很少公开的细节。此外,通过现代训练方法改进的新架构有时需要与使用过时训练方法的旧架构进行对比,例如 ImageNet 数据集上 Top-1 准确率为 76.5% 的 ResNet-50 架构。
训练方法和扩展策略对流行的 ResNet 架构有哪些影响呢?近日,谷歌大脑和 UC 伯克利的研究者给出了他们的答案。

论文链接:https://arxiv.org/pdf/2103.07579.pdf
研究者调查了现今广泛使用的现代训练和正则化方法,并将其应用于 ResNet,如下图 1 所示。在这一过程中,他们观察到训练方法之间的交互,并展示了与其他正则化方法一同使用时减少权重衰减值的益处。此外,下表 1 中的训练方法试验也揭示了这些策略的重大影响:仅通过改进训练方法,典型 ResNet 架构的 ImageNet Top-1 准确率由 79.0% 提升至 82.2% (+3.2%)。通过两个微小且常用的架构改进:ResNetD 和 Squeeze-and-Excitation,准确率更是提升至 83.4%。图 1 通过速度 - 准确率帕累托曲线描述了 ResNet 架构的优化过程:
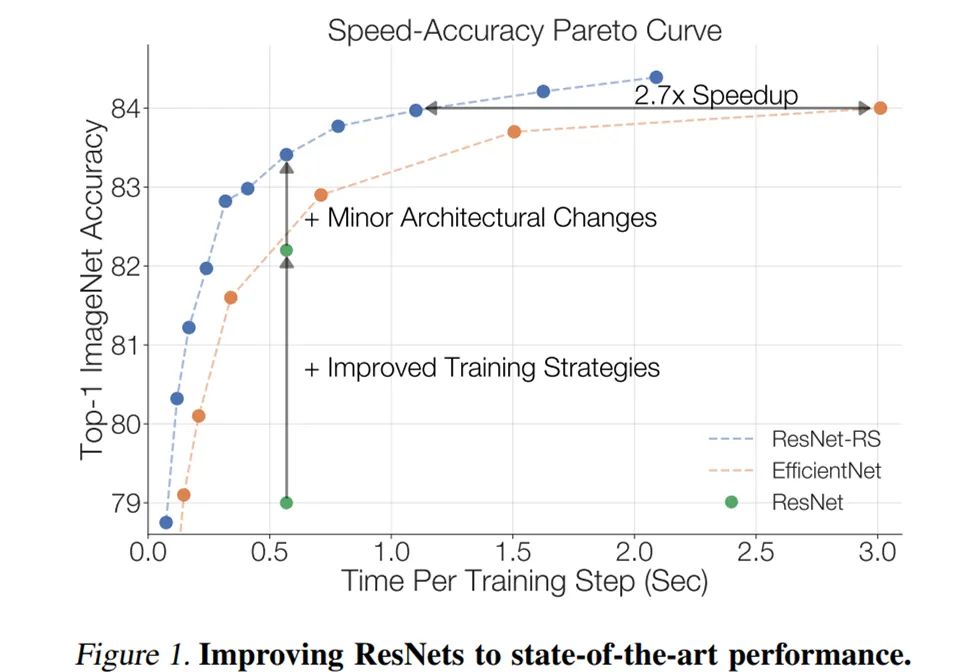
研究者还提供了扩展视觉架构的新思路和实用建议。相较于以往研究从小模型或者从少量 epoch 的训练中推断扩展策略,该研究基于对不同规模的模型执行完整的训练来设计扩展策略(如选择 350 个 epoch,而不是 10 个 epoch),进而发现最佳扩展策略与训练机制(epoch 数量、模型大小和数据集大小)之间的强依赖性。这些依赖性在小型训练系统中被忽略了,从而导致次优的扩展决策。研究者将他们的扩展策略总结如下:1)在过拟合可发生的训练设置下扩展模型深度(否则扩展宽度更可取);2)以更慢的速度扩展图像分辨率。
使用这种改进的训练和扩展策略,研究者设计了 re-scaled ResNet(ResNet-RS),它基于不同规模的模型进行训练,其速度准确率帕累托曲线如图 1 所示。ResNet-RS 模型在训练中使用了更少的内存,但在 TPU 上的速度是 EfficientNets 的 1.7-2.7 倍,GPU 上的速度是 EfficientNets 的 2.1-3.3 倍。在大规模半监督学习设置下,使用 ImageNet 和额外 1.3 亿伪标注图像进行联合训练时,ResNet-RS 在 TPU 上的训练速度是 EfficienrtNet-B5 的 4.7 倍,GPU 上的速度是 EfficientNet-B5 的 5.5 倍。
最后,研究者通过一系列实验验证了这些改进训练和扩展策略的泛化性。他们首先使用该扩展策略设计了 EfficientNet 的速度更快版本 EfficientNet-RS,它的速度准确率帕累托曲线表现优于原版 EfficientNet。接着,研究者展示了改进训练策略的性能表现在一系列下游任务上媲美甚至优于自监督算法 SimCLR 和 SimCLRv2 的表现。改进训练策略还可以泛化至视频分类任务。在 Kinetics-400 数据集上将该训练策略应用于 3D-ResNets,可以将准确率从 73.4% 提升至 77.4%(+4%)。
通过将微小的架构变化与这种改进训练和扩展策略结合起来,研究者发现 ResNet 架构为视觉研究设置了 SOTA 基线。这一发现强调了梳理区分这些因素的重要性,以便了解哪些架构表现更优。
方法
研究者介绍了基础的 ResNet 架构和使用到的训练方法。
架构
研究者介绍了 ResNet 架构以及两种广泛使用的架构变化策略:ResNet-D 修改和所有瓶颈块中的 Squeeze-and Excitation (SE)。TResNet、ResNeSt 和 EfficientNets 等多个架构使用了这两种架构变化策略。
训练方法
研究者介绍了 SOTA 分类模型和半 / 自监督学习中通常使用的正则化和数据增强方法。
研究者使用的训练方法与 EfficientNet 非常接近,训练了 350 个 epoch,但还是存在一些差异:
1)为简单起见,研究者使用了余弦学习率调度,而没有使用指数式衰减。
2)在所有模型中使用了 RandAugment,原版 EfficientNet 使用的是 AutoAugment。研究者使用 RandAugment 重新训练了 EfficientNets B0-B4,发现没有出现性能提升。
3)使用 Momentum 优化器,而没有使用 RMSProp。
研究者采用权重衰减、标签平滑、dropout 和随机深度这些正则化方法,并将 RandAugment 数据增强作为额外的正则化器。
改进训练方法
加性研究
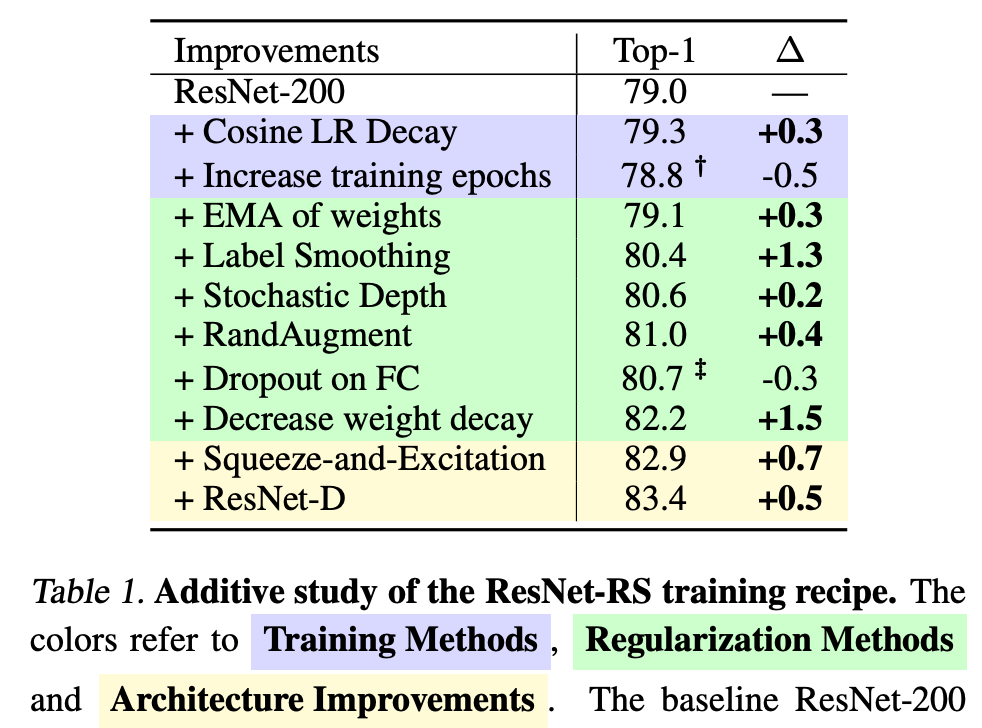
下表 1 展示了对训练、正则化方法和架构变化的加性研究。基线 ResNet-200 获得了 79.0% 的 Top-1 准确率,研究者通过改进训练方法(未改变架构)将性能提升至 82.2% (+3.2%)。添加两个常见的架构更新后(Squeeze-and-Excitation 和 ResNet-D),模型性能进一步提升至 83.4%。其中训练方法带来的性能提升占 3/4,这说明训练方法的改进对 ImageNet 性能起到关键作用。
结合正则化方法时,降低权重衰减值的重要性
下表 2 展示了在结合多种正则化方法时,改变权重衰减值的重要性:
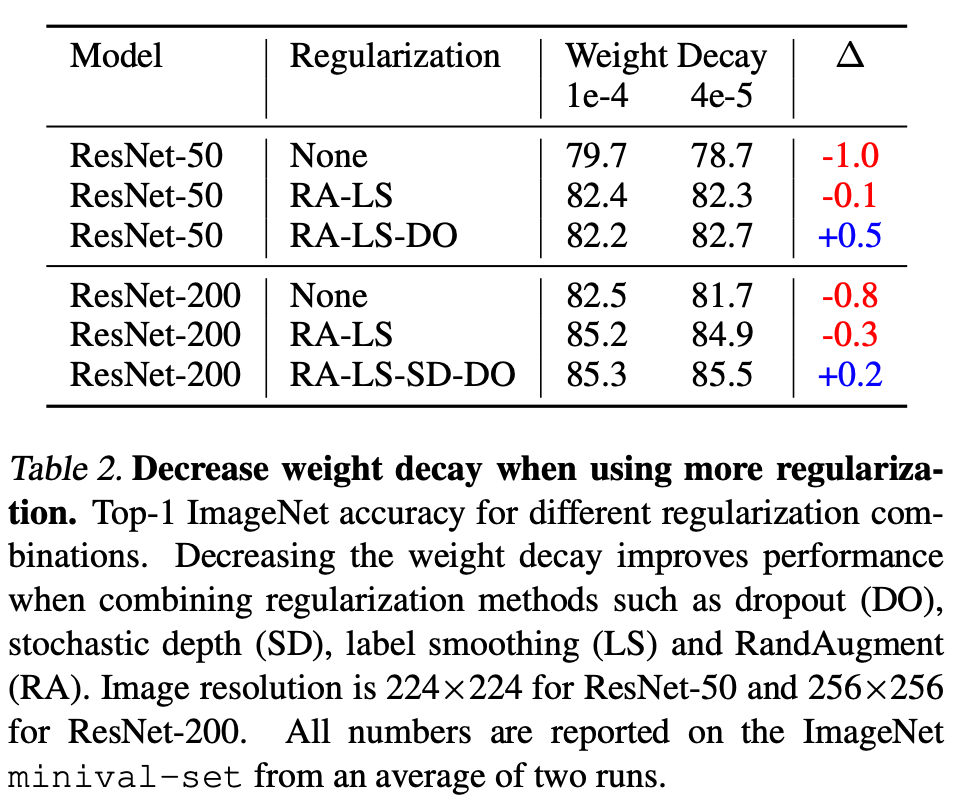
在应用 RandAugment (RA) 和标签平滑 (LS) 时,无需改变默认权重衰减 1e-4。但进一步添加 dropout (DO) 和随机深度 (SD) 之后,不降低权重衰减值会导致模型性能下降。
改进扩展策略
研究者在本节中展示了扩展策略同样重要。为了建立扩展趋势,研究者在 ImageNet 上对宽度乘法器 [0.25,0.5,1.0,1.5,2.0]、深度 [26,50,101,200,300,350,400] 、分辨率 [128,160,224,320,448] 进行广泛搜索。
该研究模仿 SOTA ImageNet 模型的训练设置,训练 epoch 为 350。随着模型尺寸的增加,研究者增加正则化以限制过度拟合。
策略 1:在过拟合发生的机制下进行深度扩展
对于较长的 epoch 机制,深度扩展优于宽度扩展。在 350 个 epoch 设置中(下图 3 右),研究者观察到,在所有图像分辨率中,深度扩展的效果明显优于宽度扩展。宽度扩展会导致过拟合,即使增加正则化,性能也会下降。他们假设这是由于扩展宽度时参数增加较大所致。因此,与扩展宽度相比,扩展深度(特别是在较早的层中)引入的参数更少。
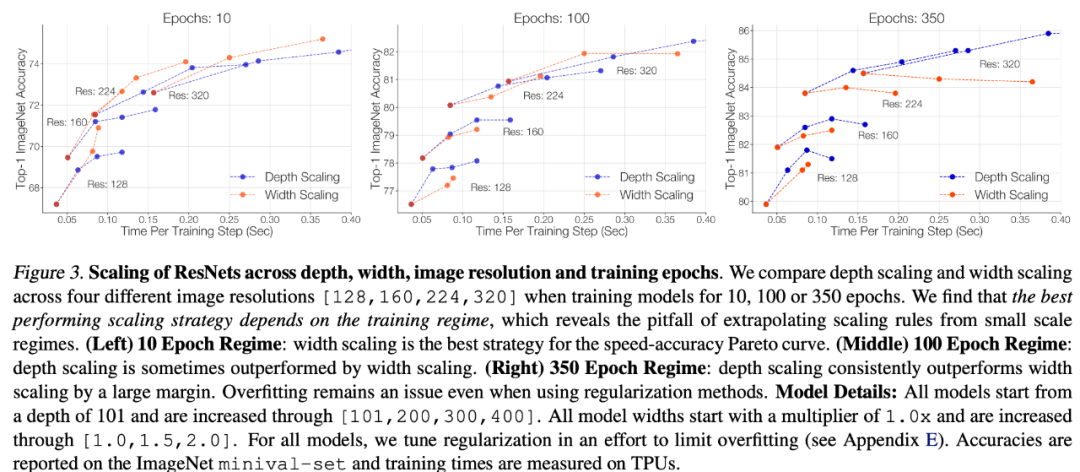
在较短 epoch 的机制下,宽度扩展优于深度扩展。相比之下,当只训练 10 个 epoch 时,宽度扩展效果更好(图 3,最左边)。
策略 2:减少图像分辨率扩展
在下图 2 中,研究者还观察到较大的图像分辨率会导致性能衰减。因此,他们建议相比以往的工作,应逐渐增加图像分辨率。实验表明,较慢的图像扩展同时提升了 ResNet 和 EfficientNets 架构的性能。
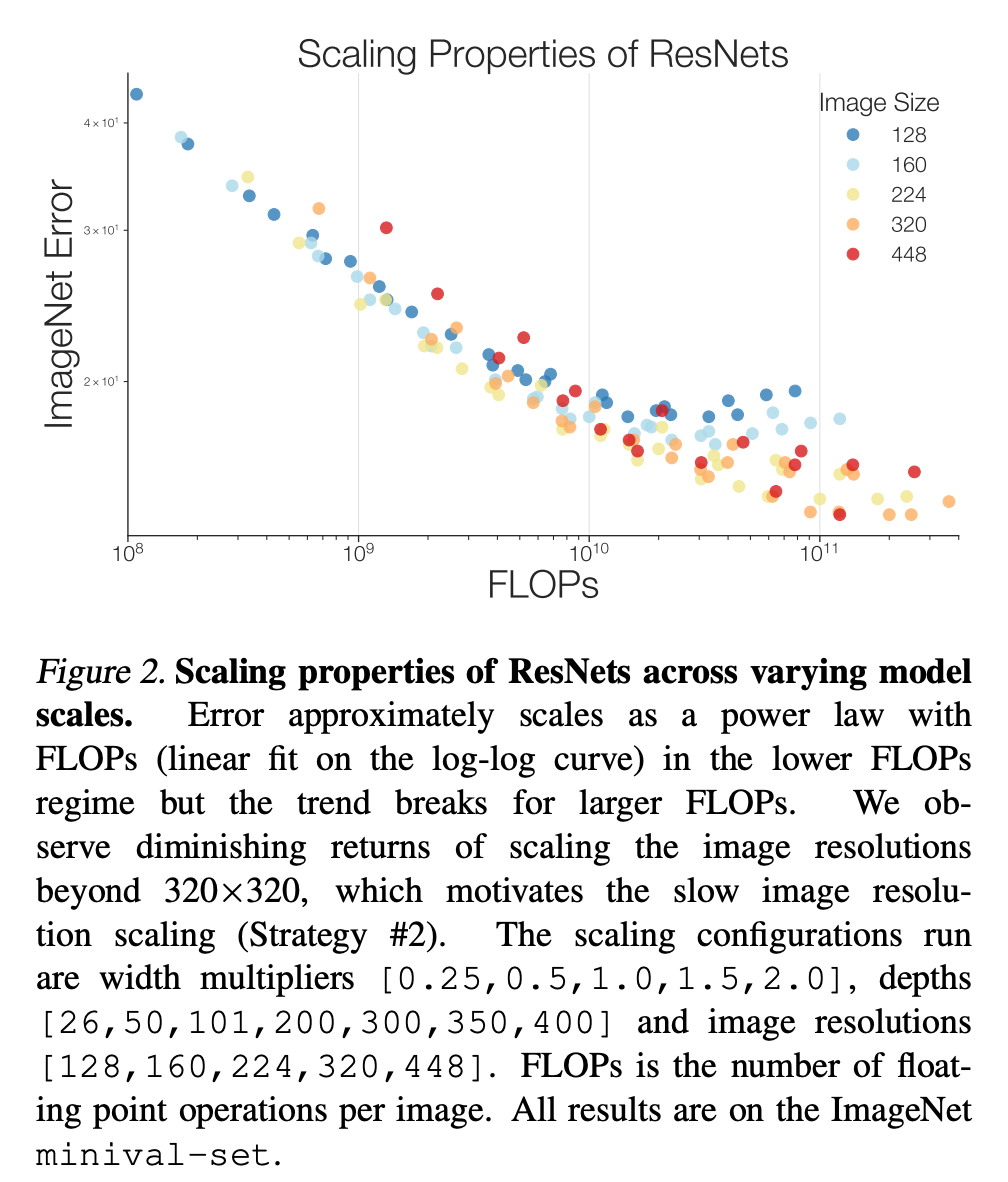
设计扩展策略的两个常见错误
1. 在小规模设置下(如小模型或少量训练 epoch)推断扩展策略:这无法泛化至大模型或更长的训练迭代;
2. 在单个次优初始架构中推断扩展策略:次优初始架构会影响扩展结果。
小结
对于一项新任务,一般推荐将一组不同规模的模型运行完整的训练 epoch,以了解哪些维度最有用。但这一方法成本较高,该研究指出如果不搜索架构,则成本将得到显著降低。
对于图像分类,扩展策略可以总结为:在会发生过拟合的设置下扩展深度,缓慢的图像分辨率扩展。实验表明,对 ResNet 和 EfficientNet 应用这些扩展策略(得到 ResNetRS 和 EfficientNet-RS)会带来相比于 EfficientNet 的极大加速。近期研究如相比 EfficientNet 实现极大加速的 LambdaResNet 和 NFNet,也使用了类似的扩展策略。
实验
ResNet-RS 的速度 - 准确率
研究者使用改进后的训练和扩展策略,设计了 ResNet-RS。下图 4 对比了 EfficientNet 和 ResNet-RS 的速度 - 准确率帕累托曲线,从中可以看到 ResNet-RS 与 EfficientNet 具备类似性能时,在 TPU 上的速度是后者的 1.7-2.7 倍。
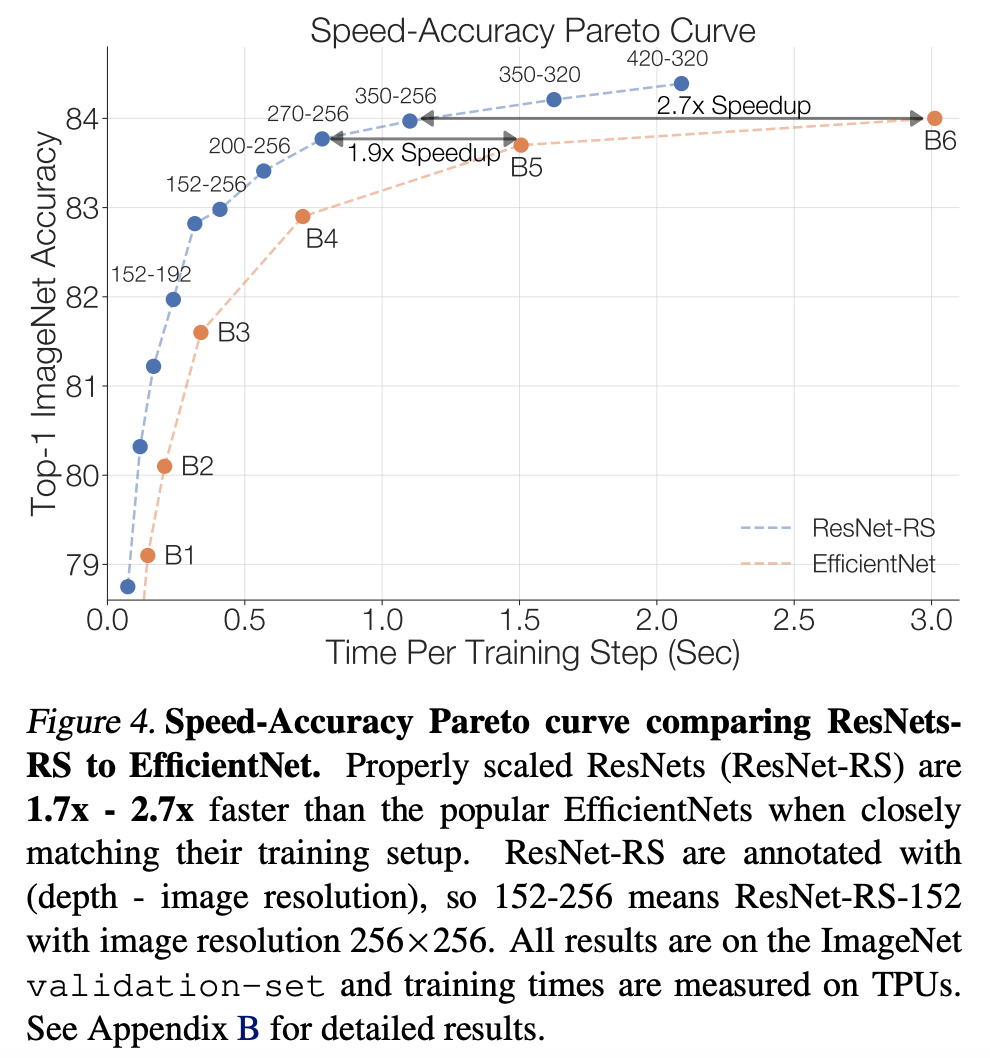
这一加速让人意想不到,毕竟 EfficientNet 的参数量和 FLOPs 相比 ResNet 有显著减少。研究者分析了原因,并展示了 EfficientNet 和 ResNet-RS 的性能对比情况,从中可以看出参数量和 FLOPs 的影响:
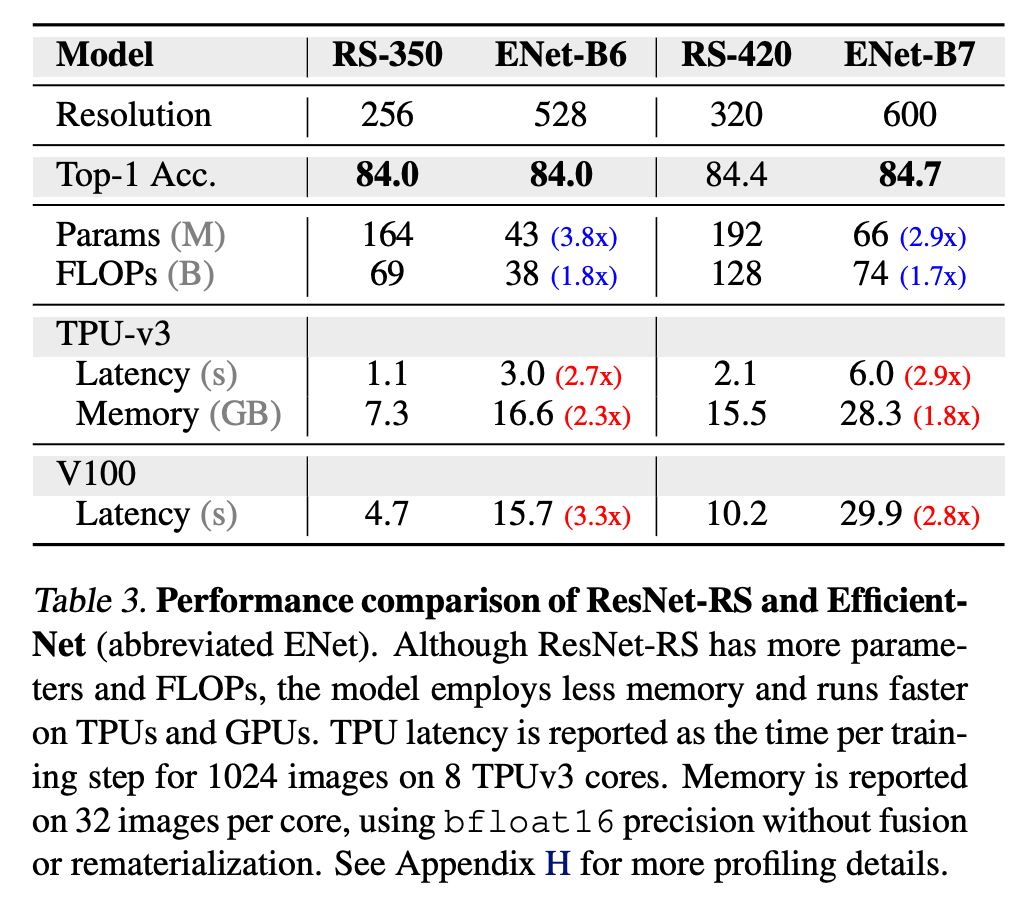
提升EfficientNet 的效率
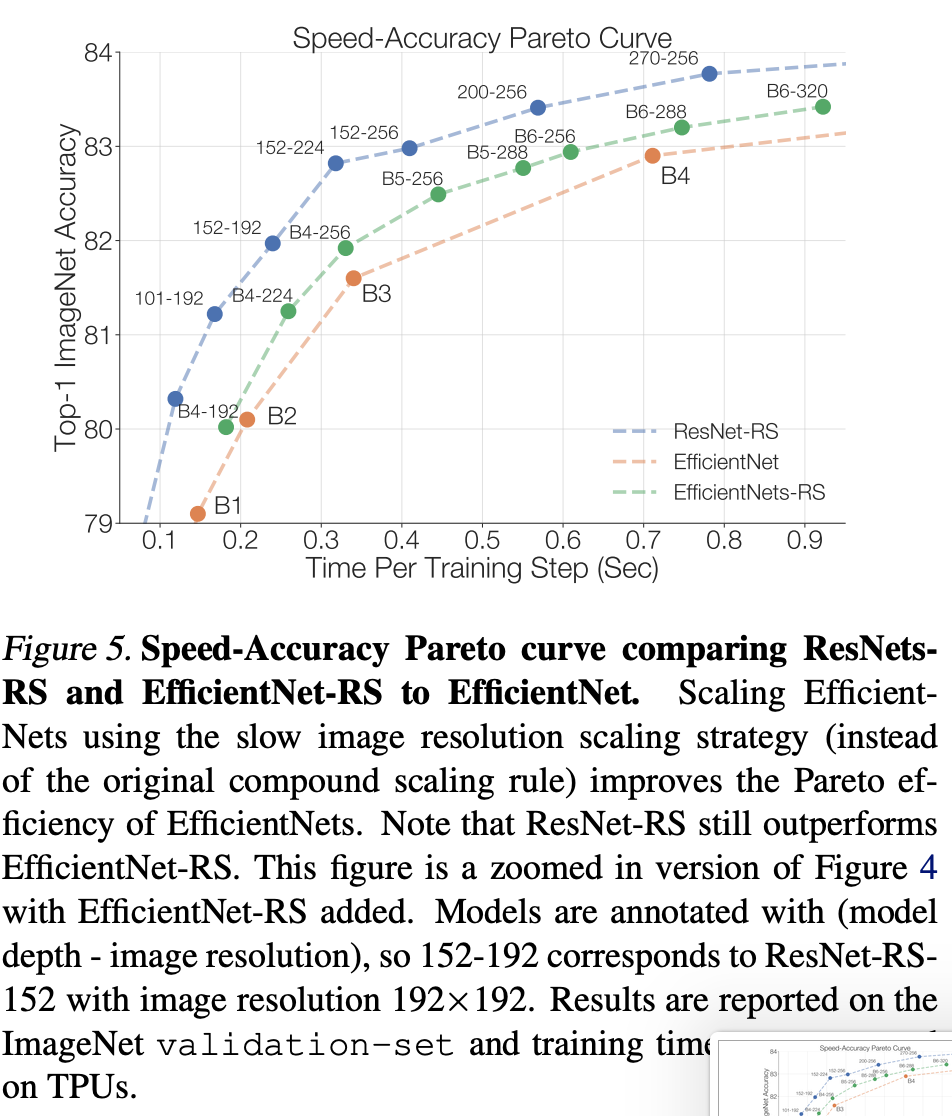
上文的分析表明扩展图像分辨率会导致收益递减。这说明 EfficientNet 倡导的扩展规则(增加模型深度、宽度和分辨率)是次优的。
研究者将 Strategy #2 应用于 EfficientNet,训练出多个图像分辨率降低的版本,并且并未改变模型的深度或宽度。下图 5 展示了重扩展后的 EfficientNet (EfficientNetRS) 相比原版 EfficientNet 的性能提升:
半监督学习
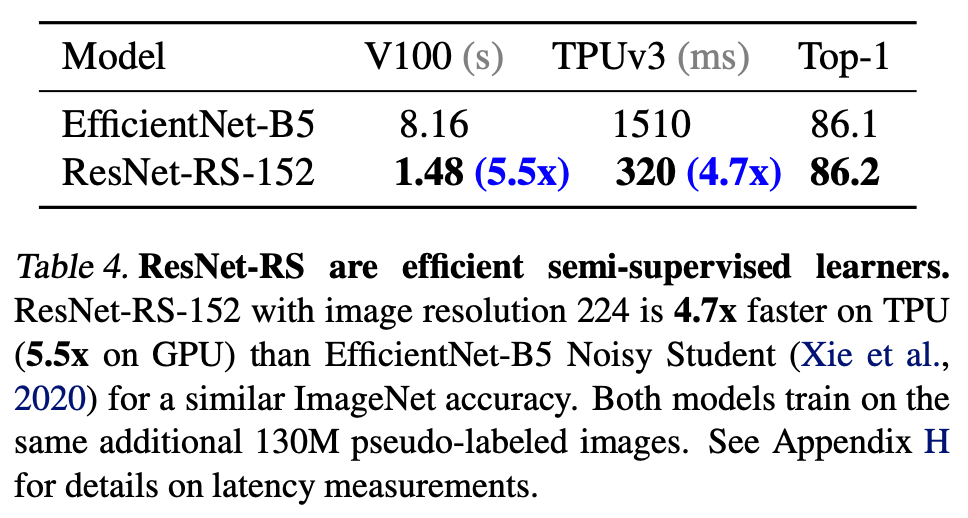
研究者在使用大型数据集的大规模半监督学习设置下,衡量 ResNet-RS 的性能。具体而言,该研究在 1.2M ImageNet 标注图像和 130M 伪标注图像上进行模型训练,训练方式类似于 Noisy Student。
下表 4 展示了 ResNet-RS 模型在半监督学习设置下性能依然强大。该模型在 ImageNet 数据集上获得了 86.2% 的 top-1 准确率,相比于对应的 Noisy Student EfficientNet-B5 模型其在 TPU 上速度快了 3.7 倍(GPU 上的速度快 4.5 倍)。
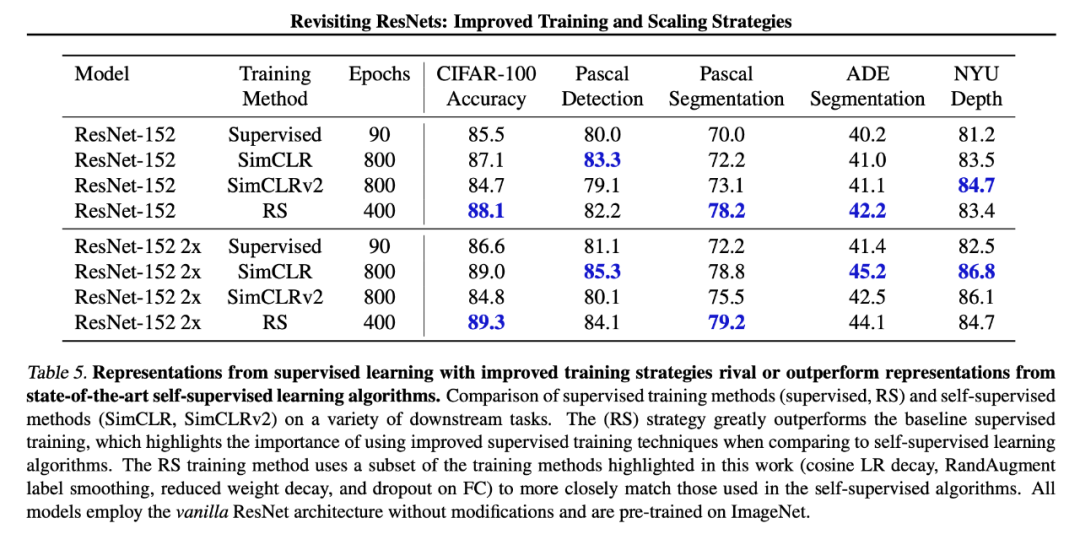
ResNet-RS的迁移学习效果
下表 5 对比了改进版监督学习策略(RS)和自监督 SimCLR、SimCLRv2 的迁移性能,发现即使在小型数据集上,改进版训练策略也能提升模型的迁移性能。
针对视频分类设计的3D ResNet
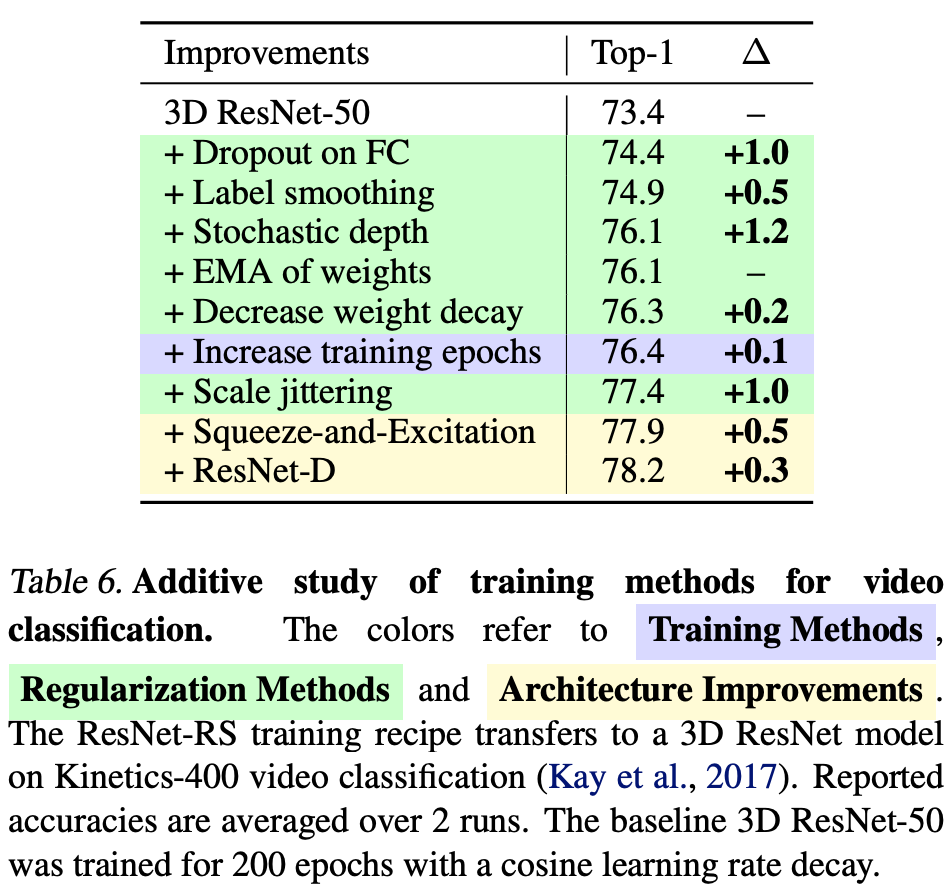
下表 6 展示了 RS 训练方法和架构改进的加性研究。将该训练策略扩展至视频分类任务,准确率从 73.4% 增至 77.4% (+4.0%)。ResNet-D 和 Squeeze-and-Excitation 架构变化更是进一步将性能提升到 78.2% (+0.8%)。与图像分类任务的情况类似(参加表 1),研究者发现大多数提升不需要架构变化。不需要模型扩展,3D ResNet-RS-50 的性能也只比 SOTA 模型的性能(80.4%)低了 2.2%。
上手实操:出海企业如何快速构建AI应用
3月17日,亚马逊云科技机器学习产品经理李媛和亚马逊云科技机器学习产品技术专家王世帅将带来线上分享。本次分享将介绍如何借助Amazon Rekognition实现用户身份识别、图片视频内容审核与借助Amazon Personalize为用户提供个性化推荐。