来源:机器之心
作者:维度、陈萍、小舟
ICLR 2021 距正式召开还有一个月的时间,今日公布了八篇杰出论文,主题涵盖复杂查询应答、图网络网格模拟以及基于随机微分方程的分数生成式建模等。此外,这八篇杰出论文中也有多位华人学者的参与。

机器学习顶会 ICLR 2021 将于当地时间 5 月 3 日至 7 日线上举行。1 月份,ICLR 2021 放出了本届会议的论文接收结果:在 2997 篇有效投稿中,共有 860 篇论文被接收,其中 53 篇 Oral,114 篇 Spotlight,其余为 Poster。
本届 ICLR 会议的接收率为 29%,相较 2020 年的 26.5% 有所提升。另外,值得关注的是,不同于 2020 年的 30 余篇满分论文,本届会议只有 15 篇论文获得了平均 8 分及以上的分数,也没出现「满分论文」。
今日,ICLR 2021 官方从 860 篇接收论文中挑选出了八篇杰出论文,研究主题涵盖利用神经链接预测器的复杂查询应答、通过图网络学习网格模拟、将主成分分析视作纳什均衡问题以及基于随机微分方程(SDE)的分数生成式建模等。
此外,在八篇杰出论文中,有多位华人学者的参与,其中一篇《Rethinking Architecture Selection in Differentiable NAS》的一作 Ruochen Wang 曾就读于上海财经大学,另一篇《Score-Based Generative Modeling through Stochastic Differential Equations 》的一作宋飏(Yang Song)本科毕业于清华大学,还曾是清华计算机科学系朱军教授的学生。

ICLR2021八篇杰出论文
论文 1:Beyond Fully-Connected Layers with Quaternions: Parameterization of Hypercomplex Multiplications with 1/n Parameters

作者:Aston Zhang、Yi Tay、Shuai Zhang、Alvin Chan、Anh Tuan Luu、Siu Hui、Jie Fu
机构:AWS AI、Google Research 等
论文链接:https://openreview.net/pdf?id=rcQdycl0zyk
摘要:近来一些研究显示出超复杂空间中表征学习的成功。具体来说:带有四元数的全连接层(四元数是指 4D 超复数),其中用四元数的汉密尔顿积代替了全连接层中的实值矩阵乘法,这种方法节省了参数,只有 1/4 的可学习参数,在各种应用中实现了可与之前的方法媲美的性能。但是,这种超复杂空间只以几种预定义维度(4D、8D 和 16D)存在。这限制了利用超复杂乘法的模型的灵活性。为此,该研究提出了一种对超参数乘法进行参数化的方法,使得模型能够从数据中学习乘法规则,而无需考虑此类规则是否预先定义。结果,该方法不仅包含汉密尔顿积,而且还学会了在任意 nD 的超复杂空间上运行。与全连接层的对应对象相比,使用任意 1/n 可学习参数可以提供给更大的架构灵活性。在自然语言推理、机器翻译、文本样式迁移和主谓词一致方面对 LSTM 和 transformer 模型进行应用的实验验证了该方法的架构灵活性和有效性。

一作 Aston Zhang 为《动手学深度学习》的作者之一,博士毕业于 UIUC,现为亚马逊高级科学家。
论文 2:Complex Query Answering with Neural Link Predictors

作者:Erik Arakelyan、 Daniel Daza、Pasquale Minervini、 Michael Cochez
机构:伦敦大学等
论文链接:https://openreview.net/pdf?id=Mos9F9kDwkz
摘要:神经链接预测器对于识别大规模知识图谱中的缺失边非常有用。但是对于回答多个域中出现的更复杂查询,如何使用这些模型尚不清楚,例如使用逻辑合取 (∧)、析取 (∨) 、存在(∃) 的查询,同时还要考虑缺失的边。该研究提出了一种框架,可以有效地回答不完整的知识图谱上的复杂查询。该方法将每个查询转换为端到端可微目标,其中每个原子的真值由预训练的神经链接预测器计算。研究者进一步分析了优化问题的两种解决方案,包括基于梯度的搜索和组合搜索。该研究的实验表明,该方法比 SOTA 方法的准确率更高,而且无需在大型复杂查询集上训练。使用少了几个数量级的训练数据,该研究在包含实际信息的几种知识图谱中将 Hits@3 从 8% 提升到 40%。最后,该研究解释了该模型用于每个复杂查询原子的中间解决方案所得的结果都是可解释的。
论文 3:EigenGame: PCA as a Nash Equilibrium

作者:Ian Gemp、 Brian McWilliams、Claire Vernade、Thore Graepel
机构:DeepMind
论文链接:https://openreview.net/pdf?id=NzTU59SYbNq
摘要:该研究提出了一种新颖的观点,将主成分分析(principal component analysis, PCA)看作竞争性游戏,其中每个近似本征向量由一个玩家控制,其目的是最大化效用函数。研究者分析了 PCA 游戏的特性以及基于梯度更新的行为,并提出了一种将 Oja 规则中的元素与泛化 Gram-Schmidt 正交化结合起来的算法,该算法通过消息传递实现了分散化与并行化。最后,该算法的可扩展性在大型图像数据集和神经网络激活的实验中获得了验证。

分散式算法1和2。
论文 4:Learning Mesh-Based Simulation with Graph Networks

作者:Tobias Pfaff、Meire Fortunato、Alvaro Sanchez-Gonzalez、Peter W. Battaglia
机构:DeepMind
论文链接:https://openreview.net/pdf?id=roNqYL0_XP
摘要:该研究提出了一个使用图神经网络来学习网格模拟的模型 MeshGraphNets。通过训练,该模型可以在网格图上传递信息,并在前向模拟过程中适应网格离散化。实验表明,该模型可以准确地预测各种物理系统的动力学,包括有空气动力学、结构动力学等。该模型的自适应性使其可以学习与分辨率无关的动力学,并能在测试时扩展至更复杂的状态空间。该研究提出的方法扩展了神经网络模拟器可以解决的问题范围,并有望提升复杂科学建模任务的效率。
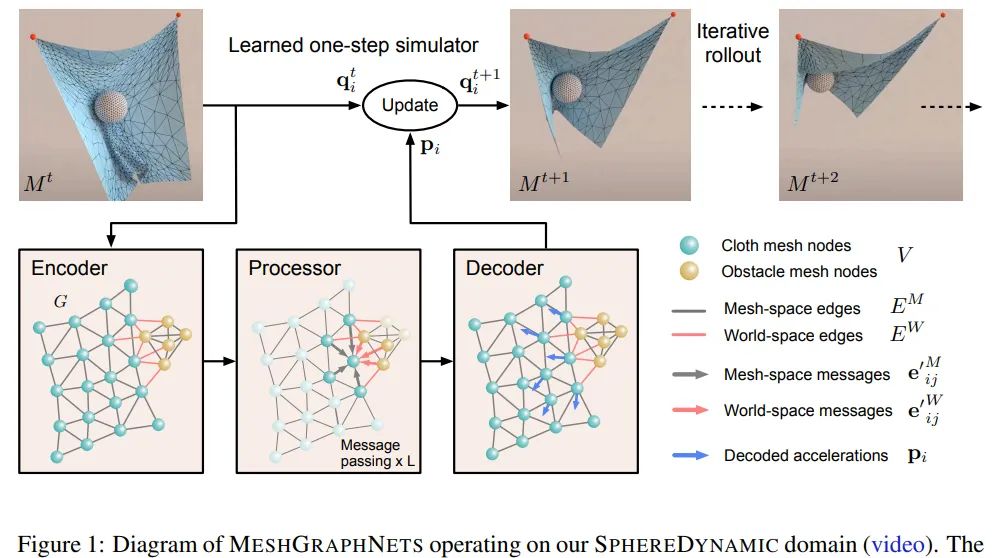
MeshGraphNets 在球体动力学(SphereDymanic)中的运行演示图。
论文 5:Neural Synthesis of Binaural Speech from Mono Audio

作者:Alexander Richard、Dejan Markovic、Israel D. Gebru、 Steven Krenn、 Gladstone Alexander Butler、 Fernando Torre、 Yaser Sheikh
机构:Facebook Reality Labs 、Pittsburgh
论文链接:https://openreview.net/forum?id=uAX8q61EVRu
摘要:该研究提出了一种用于双声道声音(binaural sound)合成的神经渲染方法,该方法可以实时产生逼真且空间准确的双声道声音。该网络以单通道音频源作为输入进行合成,根据听者相对于声源的相对位置和方向,合成两通道双声道声音作为输出。研究人员在理论上研究了 l2-loss 对原始波形的影响,并引入了一种改进的损失,克服了这些限制。在经验评估中,证实该研究提出的方法是首个产生空间准确的波形输出(由真实记录测量),无论在定量和感知研究中,优于现有的方法。
论文 6:Optimal Rates for Averaged Stochastic Gradient Descent under Neural Tangent Kernel Regime

作者:Atsushi Nitanda、 Taiji Suzuki
机构:东京大学信息科学与技术研究生院等
论文链接:https://openreview.net/pdf?id=PULSD5qI2N1
摘要:该研究分析了用于回归问题的超参数两层神经网络的平均随机梯度下降的收敛性。研究发现,神经正切核 (NTK)在基于梯度方法的全局收敛性方面起着重要作用。然而,在 NTK 机制下,仍有收敛速度分析的空间。该研究证明了通过利用目标函数和与 NTK 相关的 RKHS 的复杂性,平均随机梯度下降可以达到 minimax 最优收敛速度,并且具有全局收敛保证。
此外,该研究还证明了在一定条件下,通过对 ReLU 网络的平滑逼近,可以以最优的收敛速度学习由 ReLU 网络的 NTK 指定的目标函数。
论文 7:Rethinking Architecture Selection in Differentiable NAS

作者:Ruochen Wang、 Minhao Cheng、 Xiangning Chen、 Xiaocheng Tang、Cho-Jui Hsieh
机构:加州大学洛杉矶分校计算机科学系、DiDi AI 实验室
论文链接:https://openreview.net/pdf?id=PKubaeJkw3
摘要:可微神经架构搜索( (NAS))是目前最流行的神经架构搜索方法之一,具有搜索效率高、搜索简单等优点,这种方法通过基于梯度的算法在权重共享的 supernet 中联合优化模型权重和架构参数来实现。虽然关于 supernet 优化的讨论很多,但架构选择过程却很少受到关注。该研究根据实验和理论分析表明,架构参数的多少并不代表对 supernet 性能的贡献。
该研究提出了一种基于扰动的架构选择的替代方案,它可以直接测量每个操作对 supernet 的影响。该研究用提出的架构选择重新评估了几种可微 NAS 方法,并发现它能够从底层 supernet 中连续提取显著改进的架构。此外,研究发现,该研究所提出的选择方法可以大大改善 DART 的几种失效模式,这表明 DART 中观察到的泛化能力差的大部分原因是基于量级的架构选择失败,而不是 supernet 的完全优化问题。

论文一作 Ruochen Wang 曾就读于上海财经大学,现为 UCLA 计算机科学硕士。
论文 8:Score-Based Generative Modeling through Stochastic Differential Equations

作者:Yang Song、Jascha Sohl-Dickstein、Diederik P. Kingma、Abhishek Kumar、Stefano Ermon、Ben Poole
机构:斯坦福大学、谷歌大脑
论文链接:https://openreview.net/pdf?id=PxTIG12RRHS
摘要:该研究主要介绍了基于随机微分方程(SDE)的分数生成式建模。具体地,研究者提出了一个通过缓慢注入噪声来平滑地将复杂数据分布转化为已知先验分布的随机微分方程,以及通过缓慢地去除噪声来将先验分布转化回数据分布的逆时 SDE。非常重要的一点是,逆时 SDE 只依赖于扰动数据分布随时间变化的梯度场。通过利用分数生成式建模的进展,该方法可以准确地通过神经网络估计分数,并使用数值 SDE 求解器来生成样本。此外,研究者引入了预测器 - 纠正器框架来纠正离散逆时 SDE 演化中出现的误差,推导出了从与 SDE 相同的分布中采样的等价神经常微分方程(ODE),从而使得精确的似然计算成为可能,并提升了采样效率。

论文一作宋飏(Yang Song)本科毕业于清华大学,现为斯坦福大学计算机科学系博士生。
建新·见智 —— 2021亚马逊云科技 AI 在线大会
4月22日 14:00 - 18:00
大会包括主题演讲和六大分会场。内容涵盖亚马逊机器学习实践揭秘、人工智能赋能企业数字化转型、大规模机器学习实现之道、AI 服务助力互联网快速创新、开源开放与前沿趋势、合作共赢的智能生态等诸多话题。
亚马逊云科技技术专家以及各个行业合作伙伴将现身说法,讲解 AI/ML 在实现组织高效运行过程中的巨大作用。每个热爱技术创新的 AI/ML 的爱好者及实践者都不容错过。
©THEEND
转载请联系本公众号获得授权