来源:机器之心
作者:Lorenzo Porzi等
机器之心编译
编辑:陈萍、杜伟
高分辨率图像上的全景分割面临着大量的挑战,当处理很大或者很小的物体时可能会遇到很多困难。来自 Facebook 的研究者通过引入实例 scale-uniform 采样策略与 crop-aware 边框回归损失,能够在所有尺度上改善全景分割效果,并在多个数据集上实现 SOTA 性能。
全景分割网络可以应对很多任务(目标检测、实例分割和语义分割),利用多批全尺寸图像进行训练。然而,随着任务的日益复杂和网络主干容量的不断增大,尽管在训练过程中采用了诸如 [25,20,11,14] 这样的节约内存的策略,全图像训练还是会被可用的 GPU 内存所抑制。明显的缓解策略包括减少训练批次大小、缩小高分辨率训练图像,或者使用低容量的主干。不幸的是,这些解决方法引入了其他问题:1) 小批次大小可能导致梯度出现较大的方差,从而降低批归一化的有效性 [13],降低模型的性能 ;2)图像分辨率的降低会导致精细结构的丢失,这些精细结构与标签分布的长尾目标密切相关;3)最近的一些工作[28,5,31] 表明,与容量较低的主干相比,具有复杂策略的更大的主干可以提高全景分割的结果。
克服上述问题的一个可能策略是从基于全图像的训练转向基于 crop 的训练。这被成功地用于传统的语义分割[25,3,2]。由于任务被限定在逐像素的分类问题,整个问题变得更加简单。通过固定某个 crop 的大小,精细结构的细节得以保留。而且,在给定的内存预算下,可以将多个 crop 堆叠起来,形成大小合理的训练批次。但对于更复杂的任务,如全景分割,简单的 cropping 策略也会影响目标检测的性能,进而影响实例分割的性能。具体来说,在训练过程中,从图像中提取固定大小的 crop 会引入对大目标进行截取的偏置,在对完整图像进行推断时低估这些目标的实际边界框大小(参见图 1 左)。

为了解决这一问题,Facebook 的研究者进行了以下两方面的改进。首先,他们提出了一种基于 crop 的训练策略,该策略可以利用 crop-aware 损失函数(crop-aware bounding box, CABB)来解决裁剪大型目标的问题;其次,他们利用 instance scale-uniform sampling(ISUS)作为数据增强策略来解决训练数据中目标尺度不平衡的问题。

论文链接:https://arxiv.org/abs/2012.07717
研究者表示,他们的解决方案拥有上述从基于 crop 训练中得到的所有益处。此外,crop-aware 损失还会鼓励模型预测出与被裁剪目标可视部分一致的边界框,同时又不过分惩罚超出 crop 区域的预测。
背后的原理非常简单:虽然一个目标边界框的大小在裁剪后发生了变化,但实际的目标边界框可能比模型在训练过程中看到的还要大。对于超出 crop 可视范围但仍在实际大小范围内的预测采取不惩罚的做法,这有助于更好地对原始训练数据给出的边界框大小分布进行建模。通过 ISUS,研究者引入了一种有效的数据增强策略,以改进多个尺度上用于目标检测的特征金字塔状表示。该策略的目的是在训练过程中更均匀地在金字塔尺度上分布目标实例监督,从而在推理过程中提高所有尺度实例的识别准确率。
实验结果表明,研究者提出的 crop-aware 损失函数对具有挑战性的 Mapillary Vistas、Indian Driving 或 Cityscapes 数据集中的高分辨率图像特别有效。总体来说,研究者的解决方案在这些数据集上实现了 SOTA 性能。其中,在 MVD 数据集上,PQ 和 mAP 分别比之前的 SOTA 结果高出 4.5% 和 5.2%。
算法介绍
实例 Scale-Uniform 采样 (ISUS)
研究者对 Samuel Rota Bulo 等人提出的 Class-Uniform 采样(CUS)方法进行了扩展,创建了全新的 Instance Scale-Uniform 采样(ISUS)方法。标准的 CUS 数据准备过程遵循四个步骤:1)以均匀的概率对语义类进行采样;2)加载包含该类的图像并重新缩放,使其最短边与预定义大小 s_0 匹配;3)数据增强(例如翻转、随机缩放);4)从所选类可见的图像区域中生成随机 crop。
在 ISUS 方法中,研究者遵循与 CUS 相同的步骤,只是尺度增强过程是 instance-aware 的。具体地,当在步骤 1 中选择「thing」类( 可数的 objects,如 people, animals, tools 等),并在完成步骤 2 之后,研究者还从图像和随机特征金字塔层级中采样该类的随机实例。然后在第 3 步中,他们计算了一个缩放因子σ,这样所选实例将根据训练网络采用的启发式方法分配到所选层级。
为了避免出现过大或过小的缩放因子,研究者将σ限制在有限范围 r_th 中。当在步骤 1 中选择「stuff」类(相同或相似纹理或材料的不规则区域,如 grass、sky、road 等)时,他们遵循标准的尺度增强过程,即从一个范围 r_st 均匀采样 σ。从长远来看,ISUS 具有平滑目标尺度分布的效果,在所有尺度上提供更统一的监督。
Crop-Aware 边界框 (CABB)
在 crop 操作之后,研究者将真值边界框 G 的概念放宽为一组与 G|_C 一致的真值框。用ρ(G,C)函数计算给定真值框 G 和 cropping 面积 C,公式如下
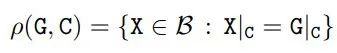
其中 X 覆盖所有可能的边界框Β。研究者将 ρ(G, C) 作为 Crop-Aware 边框(CABB),它实际上是一组边框(参见下图 3)。如果真值边框 G 严格地包含在 crop 区域中,那么 CABB 归结为原始真值,在这种情况下 ρ(G, C) = {G}。

Crop-aware 边框损失:该研究对给定的真值框 G、anchor 框 A 和 crop 区域 C 引入了以下新的损失函数:
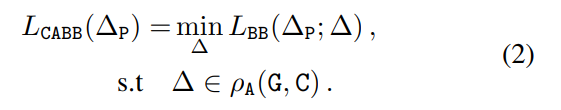
实验
研究者在以下三个公开高分辨率全景分割数据集上评估了 CABB 损失:它们分别是 Mapillary Vistas(MVD)、Indian Driving Dataset(IDD)和 Cityscapes(CS)。
网络与训练细节
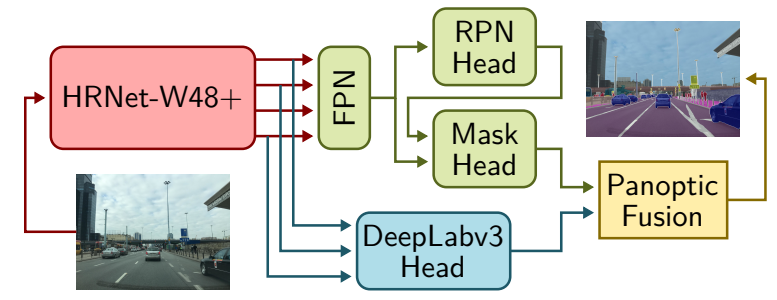
该研究遵循无缝场景分割(Seamless-Scene-Segmentation)[23]框架,并进行了修改。首先,研究者用 HRNetV2-W48+[28,6]替换 ResNet-50 主体,前者是一种专门的骨干网络,它保存从图像到网络最后阶段的高分辨率信息;其次,研究者将 [23] 中的 Mini-DL 分割头替换为 DeepLabV3+[4]模块,该模块连接到 HRNetV2-W48 + 主干。最后将同步的 InPlace-ABN [25]应用于整个网络,并在候选区域和目标检测模块中使用 CABB 损失替换标准边界框回归损失。
具体流程如下图所示:
与SOTA 结果进行比较
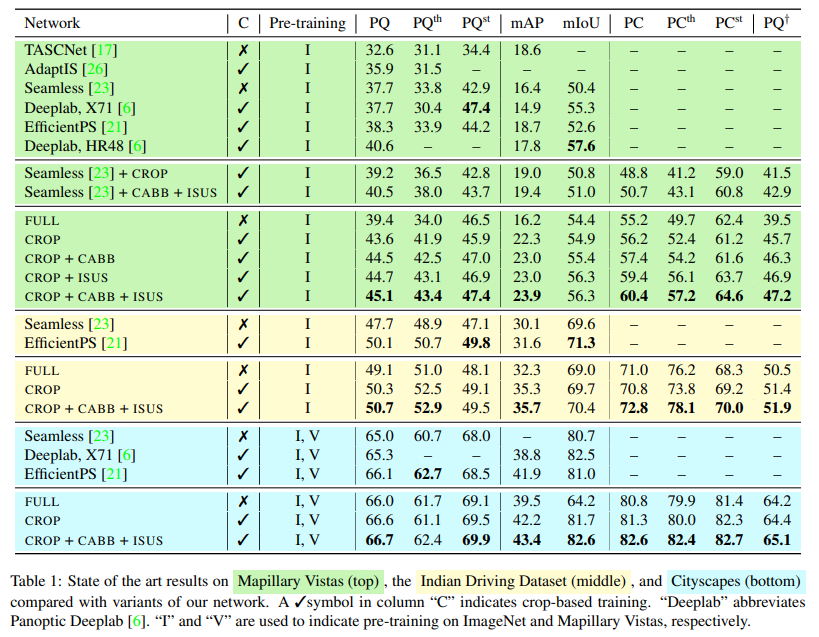
下表 1 顶部的 MVD 结果表明,CROP 在所有指标上均优于 FULL,这证明了基于 crop 训练的优势。除此以外,即使是该网络变体中最弱的,也超过了所有的 PQ 基准,唯一的例外是基于 HRNet-W48 的 Panooptic Deeplab 版本。
表 1 中间的 IDD 实验得到了类似的结果:CROP 在大多数指标上优于 FULL,而 CABB+ISUS 带来了进一步改进,在 PC 中最为显著。与之前的工作相比,该研究观察到 mAP 分数和 SOTA PQ 都有了很大的提高,而分割指标有点落后。
表 1 底部的 Cityscapes 结果呈现相同趋势,尽管边际损失(margin)有所下降。需要注意,Cityscapes 是比 IDD 和 MVD 都小的数据集,在某些度量标准中,SOTA 结果接近 90%,因此预计会有较小的改进。尽管如此,与以前最佳方法相比,CROP+CABB+ISUS 在 mAP 上实现了 1.5%以上的显著提升。
实验细节
上表 1 为均在 1024×1024 crop 上训练的两种设置的结果:从其原始代码中复制(Seamless + CROP)的未修改网络 [23],以及结合 CABB 损失和 ISUS 网络(Seamless+CABB+ISUS)的同一网络。
与该研究的其他结果一致,基于 crop 训练的引入相较基准实现了一致改进,特别是在检测指标方面,同时 CABB 损失和 ISUS 进一步提高了分数,在 PQ w.r.t.Seamelss 上提升了 2.8% 以上。
下图 6 展示了在具有大型目标的 12Mpixels Mapillary Vistas 验证图像上,CROP 与 CROP+CABB+ISUS 的输出之间的对比情况: