原标题:中国最大AI芯片问世!能组一个顶级超算集群
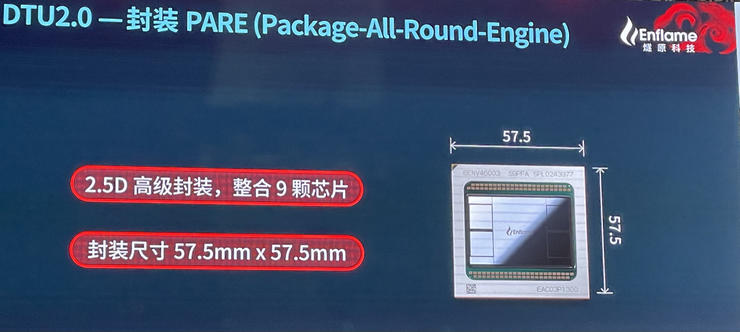
今天,中国最大AI单芯片邃思2.0在上海正式发布,这款芯片面向AI云端训练,尺寸为57.5毫米×57.5毫米(面积为3306mm2),达到了芯片采用的日月光2.5D封装的极限,与上代产品一样采用格罗方德12nm工艺,单精度FP32算力为40TFLOPS,单精度张量TF32算力为160TFLOPS,整数精度INT8算力为320TOPS。

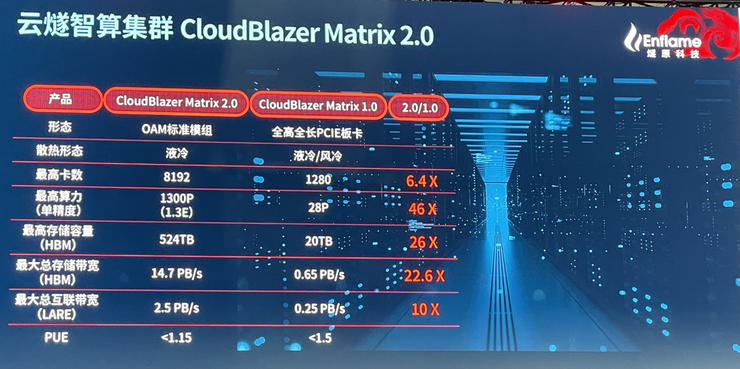
燧原科技创始人兼 COO 张亚林告诉雷锋网:“基于邃思2.0芯片打造的云燧T20加速卡支持的集群规模从上一代云燧T10的千张卡提升至8000卡,用云燧T20可以打造一个E级单精度算力集群CloudBlazer Matrix 2.0。”
E(Exascale)级计算也就是百万兆级的计算,是目前全球顶尖超算系统新的追逐目标。用一个不精确的说法来解释百万兆级计算,一个百万兆级计算机一瞬间进行的计算,相当于地球上所有人每天每秒都不停地计算四年。

那号称中国最大AI单芯片,有何特色?竞争力到底如何?

中国最大AI计算单芯片的两个“首个”
2019年底,燧原科技发布了从启动项目研发到发布用时仅18个月的云端训练芯片邃思1.0,基于邃思1.0的云燧T10加速卡单精度算力高达20TFLOPS。时隔一年半,邃思2.0和云燧T20就推向市场。之所以说“就”,是因为云端训练这样复杂的超高算力芯片通常的迭代周期是两到三年一代,如果遇上特殊情况可能还会延迟半年。

“我们第一代和第二代产品的迭代节奏快于业内速度,主要有两方面的原因,一方面是首代产品落地后得到了用户的反馈,另一方面是我们内部技术和架构的更新,催生了第二代产品。”张亚林说,“从一开始我们就强调精准执行产品路线图,第二代产品精准符合燧原的产品路线图。”
至于燧原未来是否会保持云端AI训练芯片一年半一代的更新速度,张亚林表示目前暂不方便透露,但会精准执行其产品路线图。
想要在整个行业缺芯的大背景下精准执行产品路线图显然是一个巨大的挑战,雷锋网了解到,在2020年疫情开始的时候,燧原准备了两套方案,同时发挥团队成员超过15年以上行业经验的优势,以及第一代产品开发过程中建立的供应链关系,最终保证产品的如期推出。
张亚林说:“燧原的整个供应链非常稳健,客户不必担心燧原产品的供货问题。”
在路线图精准下,为什么要把芯片面积做大?张亚林解释,燧原做芯片是高举高打,做大芯片和高端芯片是我们追求的目标,芯片的尺寸大小背后代表的是科技含量,对于中国芯片行业的贡献才是更大的价值体现。
但更大的芯片面积,就代表着更高成本。对此,张亚林表示:“一个成熟的产品必须考虑回报率(ROI)。我们需要做的是在定义产品时,计算好这个产品在市场上的整体收入和销量,从整个产品的成本角度和能够带给客户的价值定义产品。所以我们会持续关注前沿技术,但不会一味追求最新的技术,依然从芯片的性能、成本、功耗三方面考虑。”
邃思2.0的特性中,有两个中国首个,一个是首个支持TF32精度的AI芯片,另一个是首个支持最先进内存HBM2E的产品。
AI业界一直在追求用更小的数据位宽实现更高的模型精度。因此,AI模型不断优化,数据类型不断推新,AI芯片作为底层支撑就需要在支持更多数据类型的同时消耗更低能耗。
TF32代表的是张量单精度32位数据类型,相比传统的FP32,TF32在位宽更大的同时,消耗的带宽以及计算资源显著更小,被业界视为能够取代全尺寸单精度数据的革新性数据精度。
“目前业界的判断是,TF32对大部分AI场景都有应用潜力。我们紧跟国际创新者的步伐,很早就布局数据进度的研究和分析,所以才有了燧原第二代产品就支持TF32精度。”张亚林同时指出:“邃思2.0支持全精度AI精度范围,包括FP32、TF32、FP16、BF16和INT8。要用一个非常革命性的算力引擎囊括所有的精度,并且能够做到所有的精度的算力都有效,这是非常大的挑战。”
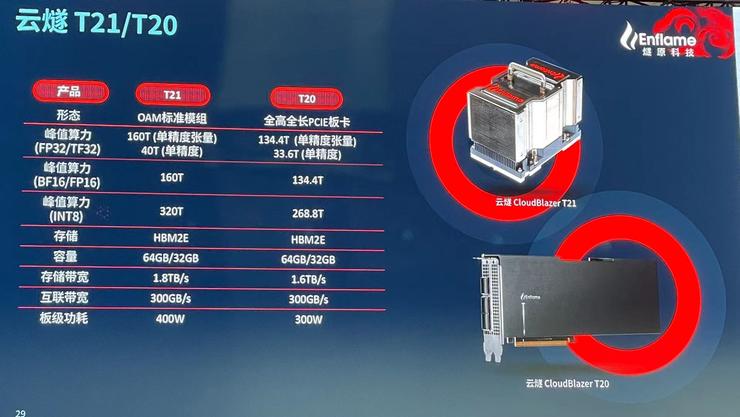
打破算力与存储之间的瓶颈,高效利用数据是AI芯片的另一大挑战。在国内最大的AI计算单芯片中,集成了4颗三星HBM2E,支持最高64 GB内存,内存带宽最高达1.8 TB/s。
“HBM2E是目前全球最快的存储芯片,通过集成4颗HBM2E,邃思2.0可以实现算力和存储带宽的匹配,实现更强算力。我们一直努力把理论算力和理论带宽匹配,有效控制整个产品的成本。采用最新的技术并不会使我们产品的整体拥有成本增加。”张亚林表示。
在燧原的产品理念中,更好的AI芯片只是构建AI系统的基础,客户最关心的并非底层AI芯片的参数。
AI芯片的比拼上升到系统级
“客户并不会直接关心芯片层面的理论参数,AI落地的时候,他们更看重的是包括硬件、软件、互联的整体解决方案的有效利用率。所以我们已经从单芯片的维度升级到了更高的系统层面。这也是燧原推出整机多卡、多卡互联、分布式软件、云端部署的一整套交钥匙解决方案的原因。”张亚林说道,“我们也更强调通过低碳绿色化的云燧智算集群服务客户。”
AI芯片的比拼要升级到AI系统的比拼,从用户角度,对比AI系统的维度就会包含五个:软硬件一体的性价比、能效比、易用性、迁移成本、范化性。
既然是系统,互联技术非常关键。目前,业界通过不同的远程直接内存访问技术(RDMA)进行互联,比如InfiniBand、iWARP、RoCE。燧原采用的是自研GCU-LARE互联技术实现云燧AI加速卡的多卡集群互联,同时兼容业界其它RDMA技术便于与其它系统互连。
据介绍,燧原自研的GCU-LARE多卡集群互联技术,支持6个带宽50GB/s的卡间传输端口,总带宽达到300 GB/s。
GCU-LARE具备两大特色,一个是不需要传统互联技术的连接卡或桥接卡,可以直接通过线缆的方式直连,降低成本。另一个是能够根据用户的需求和机房的实际情况,定制不同的拓扑结构,能够轻松构建4000卡以上的大型训练集训拓扑,实现定制化集群产品CloudBlazer Matrix。
在云燧T20的发布会上,燧原发布了云燧智算集群 CloudBlazer Matrix 2.0,最高可实现1.3E(130000T)的单精度只能算力集群。
“云燧的互联接口在单口速度保持不变的前提下,接口数量从T10的4个增加到T20的6个,带宽提升150%。用云燧T20可以打造中国E级单精度算力集群。”张亚林表示。
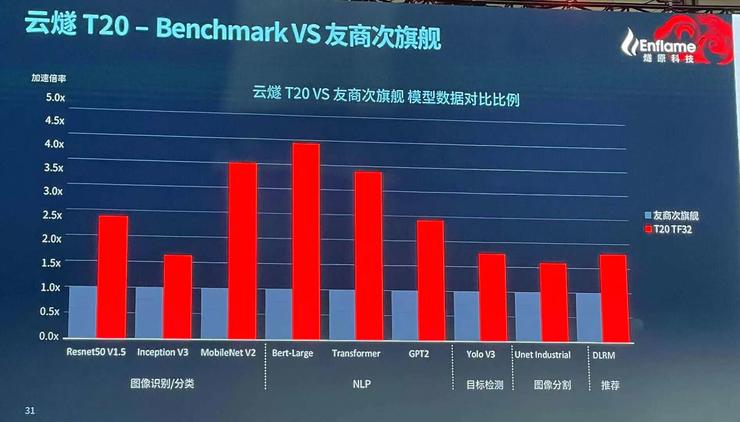
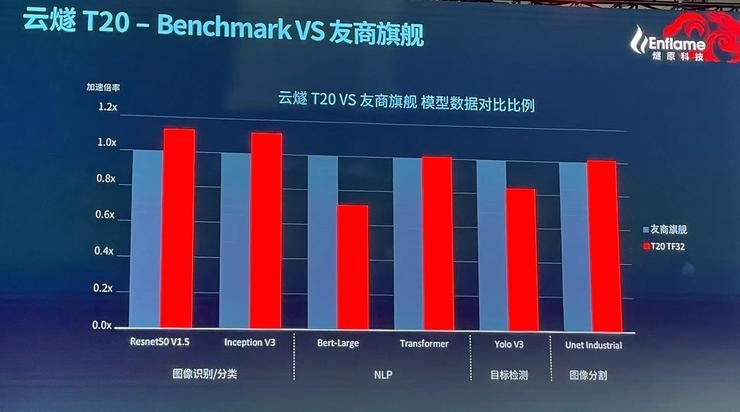
“在软件易用性和迁移成本方面,我们投入了大量精力。”
与云燧T20一起发布的还有软件平台驭算2.0,进行了多方面提升,包括:为用户提供高度契合业界标准的编程接口,以支持高性能自定义算子开发;全面优化的动态性模型支持;引入业界先进的MLIR编译框架;基于启发式自适应方法的算子泛化实现以及图优化策略,可以广泛支持更多标准模型和自定义模型训练。
张亚林介绍:“驭算2.0的重点是提升易用和泛化,同时也能降低迁移用户的成本。我们的产品从第一代开始就采用的热启动的方式降低用户的迁移难度和成本,也就是在进行硬件架构设计的时候就已经考虑了客户的需求,在落地的时候得到了客户认可。如今第二代产品,同样采用热启动的方法,使用更多的用户反馈进一步降低迁移难度和成本。”

“在软件层面,现在业内比较通用的两个AI框架是TensorFlow和Pytorch,如果他们的模型完全基于框架开发,切换到燧原的产品只需要硬件切换,软件可以无缝切换。软硬件一定是一体化,也只有软硬一体化设计才对客户有更高价值。”张亚林进一步表示。
因此,驭算2.0还支持资源虚化、重组以及系统级设备虚拟化,使用户在业务部署和资源整合上可拥有更为灵活的方法;支持4000卡规模以上的集群分布式训练;升级系统兼容性方案、部署方案和RAS,支持主流操作系统最新发型版,开箱即用,简化客户定制系统集成,对客户的部署和运维更加友好。
实际上,芯片实力的比拼从来都不是单芯片的比拼,而是系统和生态实力的比拼。纵观目前全球前几大芯片巨头,持续迭代的芯片只是其保持竞争力的基础,围绕芯片的互联技术、软件栈以及不断拓展的生态才是竞争的护城河。
燧原既然已经从单芯片的能力拓展到系统层面,那如何挑战云端训练芯片的霸主英伟达?
聚焦三个业务群,与霸主差异化竞争
“作为一个追赶或者新生者,差异化竞争是必然的。燧原进行差异化竞争时一直注重三个部分,第一是我们提供的算力性价比一定要越来越好,第二是中国有最丰富的业务场景,也有最丰富业务场景使用者,所以我们与最丰富的业务场景做更多深入的结合,并进一步做业务场景的泛化,第三就是本土化、定制化、客户的服务开发。”张亚林说。