来源:机器之心

本文有四大亮点
十万美金奖金赛事的冲击诀窍大公开
13个Cifar-10模型和2个Imagenet模型的下载地址+密码
IMAGENET数据集和相应的IMAGENET的预训练模型下载
阿里安全2021校招20+岗位的内推路径
十万美金背景
阿里安全、清华大学和UIUC共同主办CVPR2021安全AI挑战者计划第六期,打造AI安全国际赛事。共计10万美金现金奖励,召集“挑战者”以攻击者或防守者的身份共同打磨AI模型安全;为广大安全爱好者提供数字基建安全的试炼场,在高难度的真实环境中提升技术。
 图为赛事组委会
图为赛事组委会两个赛道,全球唯一;全球首个提供在线运行环境的白盒对抗攻击竞赛+全球首个在线测试的无限制对抗样本竞赛。
该比赛针对当前人工智能安全研究的热点问题,围绕不同防御模型对抗攻击和无限制对抗攻击两个具有挑战性的前沿问题,邀请国际顶尖大学和研究机构的相关研究者参赛,力争探索新型的人工智能算法,推动人工智能理论、技术和应用的发展。竞赛由阿里云天池平台提供云上竞赛环境,
赛事详情点击10万美金!CVPR2021人工智能安全顶级国际
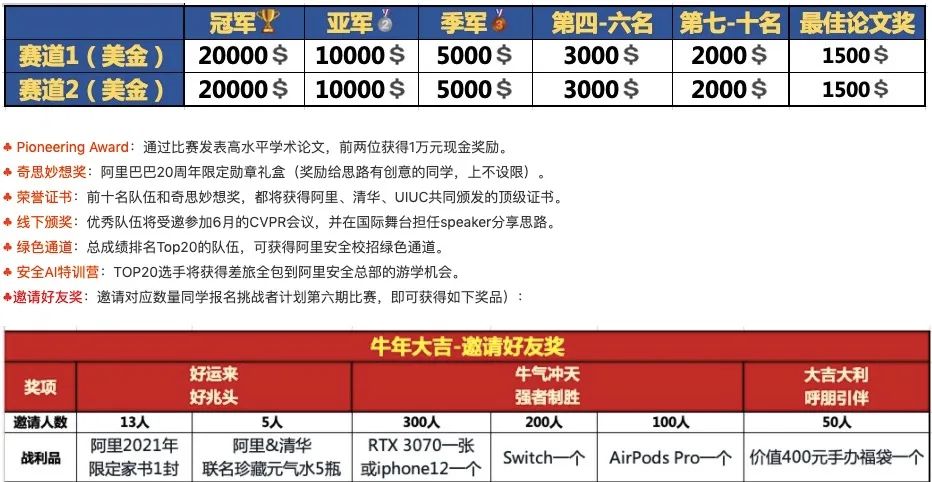 图为奖励设置
图为奖励设置赛道一解析:防御模型白盒对抗攻击
1题目背景
要知道目前很多对抗防御方法被提出以减轻对抗样本的威胁。但是,其中一些防御可以被更强大或更具针对性的攻击攻破,这使得很难判断和评估当前防御和未来防御的有效性。本次比赛的目的就是对防御模型进行全面而正确的鲁棒性评估。
2 题目赛况
2.1 赛题简介
2.2 数据介绍
比赛方通过15个防御模型测试选手提交的攻击算法,其中包括13个在CIFAR-10上训练的模型和2个在ImageNet上训练的模型,比赛方将会利用CIFAR-10测试集的前1000个数据和ImageNet ILSVRC 2012验证集中随机挑选的1000个数据进行测试。为了方便查阅我将其整理成如下表格:

表1模型介绍
举办的比赛方很贴心,他们已经将这些模型链接的下载程序https://github.com/thu-ml/ares/tree/contest 中,如下图所示,为各个模型下载的程序。
需要注意的一点是这些预训练好的模型大部分存储在google 的Drive云端中,所以需要梯子来进行下载。
为了能够让大家更加方便的去获取模型我将这13个Cifar-10模型和2个Imagenet模型存放到百度云盘中。下载模型的链接和密码分别为:
链接:
https://pan.baidu.com/s/13Je6K5TjNeGiReAtOUBfew
密码:CVPR
2.3 评价指标
本次比赛的提交评测,在主办方提供的ARES评测平台上进行。
平台的链接为:
https://github.com/thu-ml/ares/tree/contest

选手需要提交白盒攻击算法的源代码(不同于以往,之前需要提交对抗样本)。这些提交将会在范数扰动下进行评测。对于CIFAR-10上的模型,对抗扰动规模是,对于ImageNet上的模型,扰动规模是。提交的攻击算法可以获取到白盒模型的信息,但是仅仅可以获得模型的logits输出,然后在此输出的基础上设计攻击目标函数或者梯度更新方式。
需要注意的是基于模型特征上的白盒攻击算法不被允许。本次比赛鼓励参赛者开发出“通用”的攻击算法,使得它们不是针对某一个模型特制的,而是对于所有模型都可以达到很好的攻击效果。
通过防御模型的分类错误率作为提交攻击的得分(越高越好)。计算公式如下:
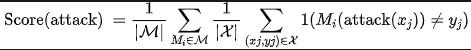
其中是所有待攻击模型,是评测数据集。选手需要保证攻击算法返回的对抗样本距离原始样本小于,否则平台将会自动进行clip裁剪。
3 提交文件介绍
本次比赛提交的是攻击代码,而不是在本地生成的对抗样本。每个提交都是一个名为 Attacker.zip (或者是attacker.zip )的Python软件包的zip 压缩包。在__init__.py 中实现自己的对抗攻击类,主办方为了实现接口的统一,需要调用ares.attack.base中的抽象类BatchAttack对其进行改写,类中共包含3个函数,分别是 __init__(),config(),batch_attack() 。
__init__() 函数接受4个参数:model, batch_size, dataset, session。
model是ares.model.base.ClassifierWithLogits的实例。可以用过调用
model.logits(xs)得到模型的logits输出,进而通过调用tf.gradients() 计算模型梯度。其还提供了模型的其他信息,比如模型的输入数据范围[model.x_min, model.x_max], 模型输入数据的维度model.x_shape。
batch_size是对于模型建议的batch_ size。需要通过此batch_ size 对模型进行调用。我们保证了充足的GPU内存。batch_size在CIFAR-10上是100;在ImageNet上是20。
dataset是“imagenet”或“cifar10”的字符串。
session是tf.Session的实例。模型将会读入此session。需要通过此session运行模型。
config函数接受关键词参数kwargs,将扰动通过kwargs[“magnitude”]传入,此函数的返回值被忽略。
batch_attack函数接受3个参数: xs, ys, ys_target。
xs是原始样本。需要对其产生对抗样本。xs是numpy格式的数组, 其维度为(batch_size, *model.x_shape)。
ys是对应的真实类别。
ys_target用于目标攻击,在此次比赛中没有用到,将被设置为None。
主办方在评测的过程中需要对提交的攻击限制时长:
每个数据的平均梯度计算次数应少于100次
平均模型预测次数应少于200次
所有模型的总运行时间应少于3小时
4 实际提交
在提交自己的代码之前一定需要现在本地的实验环境中先跑通否则就会各种报错,如下图所示:
我提交的是PGD攻击的样例代码,可以得到44.07的分数,进一步的攻击还在尝试中。

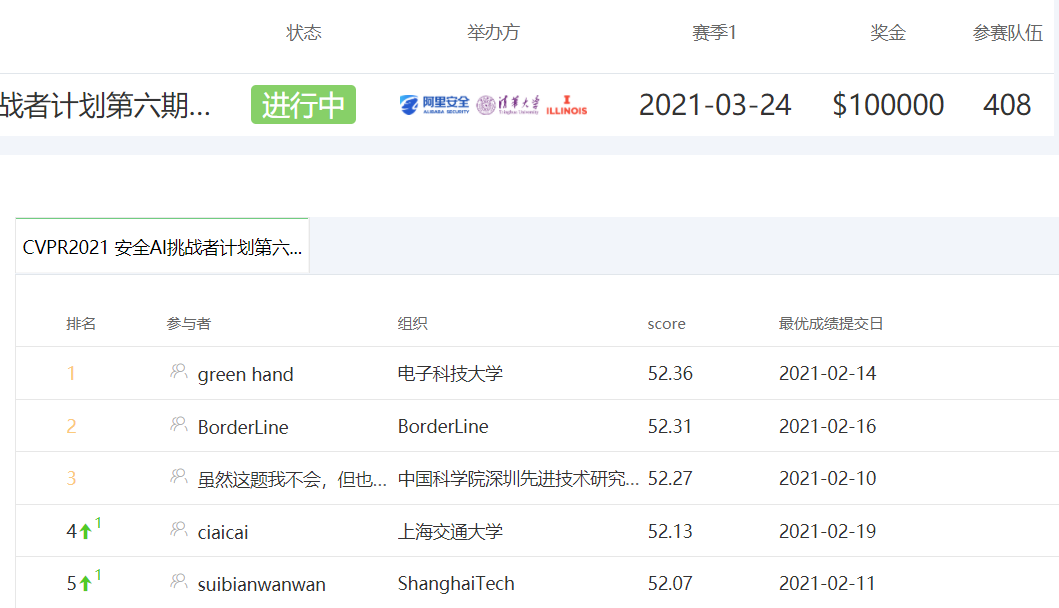
总体的排行榜如下所示,最高分是52.36分。
赛道二解析:ImageNet无限制对抗攻击
1题目背景
在ImageNet分类任务上,近年来出现了多种评测模型在不同场景下鲁棒性的衍生数据集,这些数据集都没有限制改动图像和原图之间的相似性,而是要求攻击图像更贴近现实世界存在的噪声。
本次比赛的目的是更贴近实际攻击性更强的生成无限制对抗扰动的方式。同时通过多种无限制攻击测试帮助理解当前深度模型脆弱之处并构建更鲁棒的分类服务。
2 题目赛况
2.1 赛题简介
2.2 数据和提交文件
所有图像筛选自ImageNet数据集,这些图像都被resize到500 *500的大小,提供的标签文件dev.csv存储着每张图的标签。IMAGENET数据集有135G,从官网下载速度特别慢每秒只有50k左右。

为了能够让大家更加方便的获取IMAGENET数据集和相应的IMAGENET的预训练模型我把它们上传到了百度云。
IMAGENET分类模型1:https://pan.baidu.com/s/1cvSLdjt015JOYiZkVvZHow,密码:free
IMAGENET分类模型2:https://pan.baidu.com/s/1JS97GLJiM6TWnyDJHMtsnA,密码:fast
IMAGENET数据集:
https://pan.baidu.com/s/1Ci5ThmfXaM1jcAH5yx2Hgw,密码:2012
初赛和复赛都需要选手提交扰动好的样本,提交方式是一样的,参赛选手需要上传一个压缩包,其中包含5000张修改后的图像,图像的尺寸、命名、文件格式(.jpg)应和原始图像保持一致。保证所有的图片不改变命名,存放于images文件夹中,如下所示:

之后将整个文件夹打包成images.zip上传。
3 评测打分
本次评测打分分为两部分,一部分是客观机器打分指标,一部分为主观人为打分指标。
3.1 客观评价指标
假设原始N张图像为,对于选手提交的个无限制攻击样本,主办方主要测试三个方面:
3.1.1 攻击性
比赛主办方直接计算选手提交样本在后台模型上的攻击成功率来代表攻击性,这个值在0到1之间具体的计算公式为:

其中为后台模型的输出。
3.1.2 自然真实程度
FID(Frechet Inception Distance score,FID)是计算真实图像和生成图像(在这里特指对抗样本,它广泛应用在GAN中)的特征向量之间距离的一种度量。假如一个随机变量服从高斯分布,这个分布可以用一个均值和方差来确定。
那么这两个分布只要均值和方差相同,则这个分布相同。利用均值和方差来计算这两个单变量高斯分布之间的距离。一般情况下样本是一个多维的分布,所以需要用到协方差矩阵(用来衡量两个维度之间的相关性)。
这种使用均值和协方差矩阵来计算两个分布之间距离的计算公式如下所示:

其中,和分别表示随机变量的均值和协方差矩阵。和分别表示随机变量的均值和协方差矩阵。
由上公式可知,FID分数越小代表着生成分布和真实图片之间越接近。
举办方为了限制选手提交的图像具备自然真实的特性,用FID(参考论文为《GANsTrained by a Two Time-Scale Update Rule Converge to a Local NashEquilibrium》)来作为图片自然性指标,具体的计算公式如下所示:
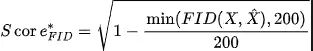
与FID的变化趋势正好相反,分数越大代表着生成分布和真实图片之间越接近。具体的计算的github代码也相应的给出来了。
3.1.3 原图像感知距离
加入这个指标主要是为了防止选手人为挑选一些和原图极为不相似的网上公开样本作为提交,感知距离是一种比传统SSIM,PSNR等更优的图像一致性度量指标,最先由论文《TheUnreasonable Effectiveness of Deep Features as a PerceptualMetric》提出,公式如下:
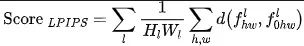
其中和分别为和为输入,在VGG的第层特征,为某一个距离度量指标。经过规范化的计算公式如下所示,主办方还提供了相应的github 计算代码。
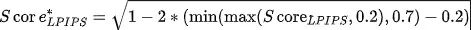
整体的客观机器打分计算为:
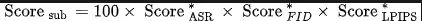
3.2 主观人为打分
在比赛的最终阶段,参赛选手需要针对5000个图片进行无限制攻击。最终阶段选手提交的得分会经过人工打标,对图像的语义以及质量两方面进行主观打标。
3.2.1 图像语义人工标注
图像语义标注主要是对攻击前后的图像进行判定,图像的语义是否发生变化,从而用于判定是否是有效攻击。如果图像语义发生变化,就算模型识别出错,也定义此次攻击失败。只有保留了图像语义并且模型识别出错的才算攻击成功。每次标注会给出原图+无限制攻击后的图,然后由打标人员判断,无限制攻击后的图像的语义是否发生变化。因为语义标注比较主观(举办方会把每个pair分配给5个人员进行标注,最后使用5人多数投票决定的得分作为图像的语义分。
判断语义是否发生改变的形式可以归结为4条:
引入新的目标以混淆语义。该做法类似的有MixUp,CutMix,多图拼接等,主观打分时比赛主办方会对比原图判断选手是否在图像中引入了新的目标,若是,则判定为语义变化,否则正常。
旋转平移缩放。适度的图像仿射变换是不影响语义的,但是若参赛选手使用了大范围的平移或者旋转,导致目标部分移出边界,或者旋转后影响语人为识别,则判定为语义变化。
抛弃图像原有信息(例如灰度化,模糊,压缩或者只使用边缘信息)。同样的,若这些抛弃图像颜色纹理细节的操作,不影响人为识别,可视为正常,否则判定为语义变化。
风格迁移等改变目标颜色或者纹理的方法,同样的,若这些抛弃图像颜色纹理细节的操作,不影响人为识别,可视为正常,否则判定为语义变化。
3.2.2 图像质量人工标注
图像质量人工标注是对攻击前后的图像质量的变化进行定量标注,用于判定生成的无限制对抗图像的质量,语义人工标注一样,图像质量也会采用pair对的形式,对攻击前后的质量下将程度进行标注。我们对图像质量的标注进行了定量,分成5个级别,定义如下:
级别1:图像质量极差,只能勉强辨认目标。
级别2:图像质量较差,有视觉上的干扰,不能一眼辨认。
级别3:图像质量一般。
级别4:图像质量较好,可以清晰辨认目标。
级别5:图像质量最高,原图和攻击后的图从视觉上基本一致。
最后提交的5000张图中,只统计攻击成功样本的主观分。每个pair对会分配5人进行标注,最后使用5人打标的平均分作为该图像的质量分,最终的总的主观评估得分为:

4 实际排行
总体的排行榜如下所示,最高分是来自华南农业大学队伍的84.63分。
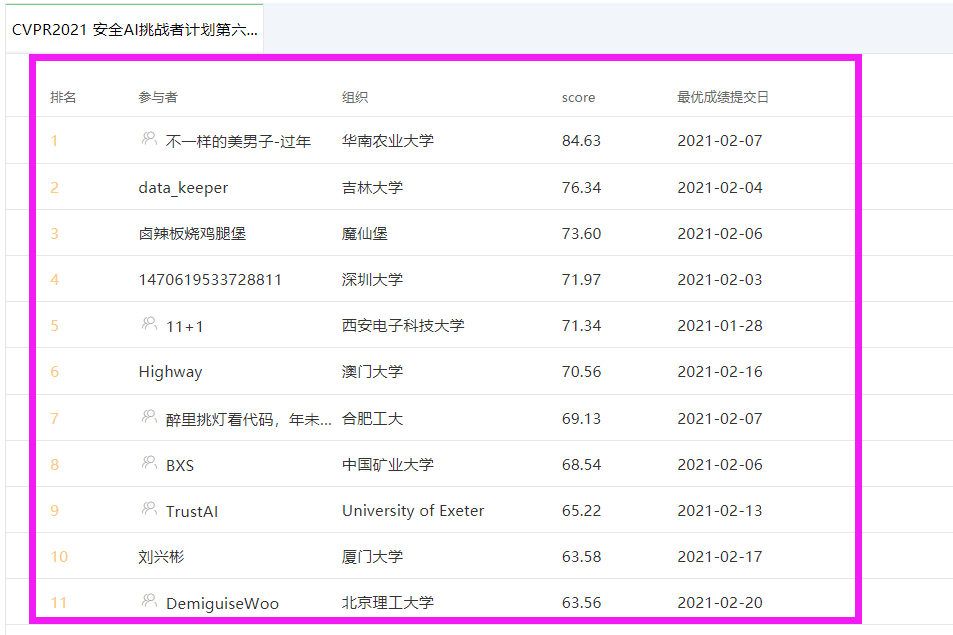
客观评分很高,并不一定意味着最后的得分会很高,需要注意如下几点:
不要试图通过黑盒迁移攻击的方式来提交样本,一开始可能混熟摸鱼混过去,但是这会导致一些在初赛有效的黑盒迁移攻击直接失效。
不要试图去过拟合客观机器打分指标,一些图像质量,自然性指标是可以拟合且得到高分的,但是这些过拟合的提交通常在人工审核阶段引入主观指标后会大大降低得分。
不要引入其他语义信息,使用MixUp,Cutmix等技巧可能可以得到较高的客观分,但注意比赛最终的排名是由主观分来确定,对于MixUp,Cutmix获得的样本,很可能在人工审核阶段无法得分。
2021阿里安全春招内推来袭!