来源:机器之心
编辑:张倩、蛋酱
「求帮忙把背景 P 成五彩斑斓的黑,可以吗?」
有人认为,自然语言将是软件的下一代接口:你有什么需求,「告诉」它就行了,剩下的不用你管。这种「动动嘴皮子就能把事儿办了」的场景似乎也越来越多。
在最近的一篇论文中,来自希伯来大学、特拉维夫大学、Adobe 等机构的研究者提出了一种名为「StyleCLIP」的模型,几乎可以让你动动嘴皮子就把图修了。
这里用「几乎」是因为研究者给出的接口其实还是文字版的。如下图所示,如果你想让一只猫看起来可爱一点,只需要输入「cute cat」,模型就能够把猫的眼睛放大,同时改变其他影响其可爱值的特征。
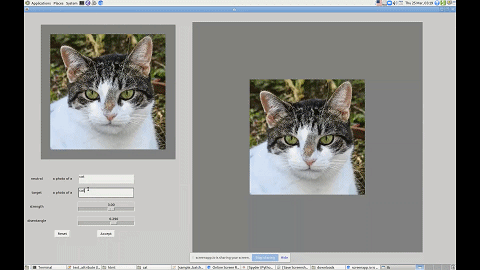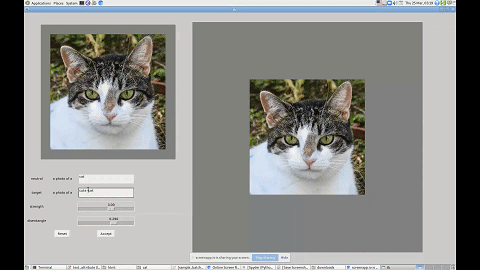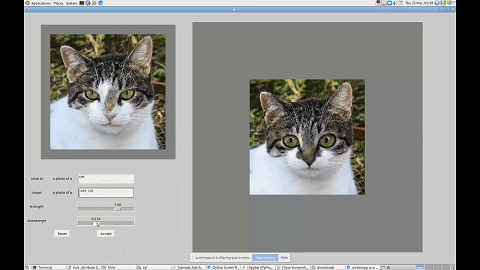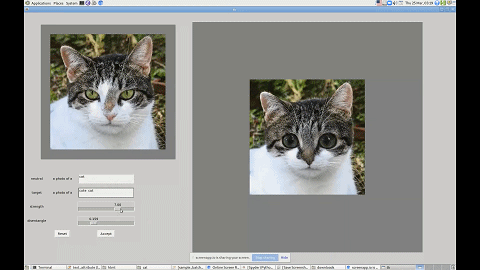
利用这个界面,你还可以改变图中人物的发型、性别等特征。
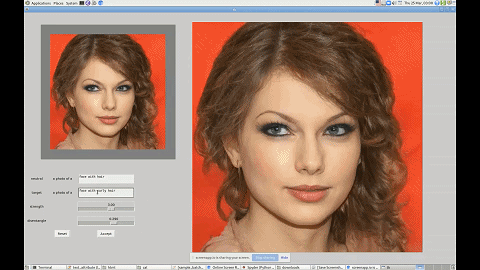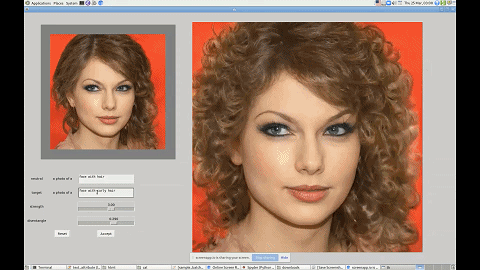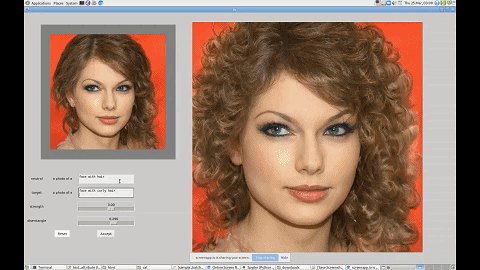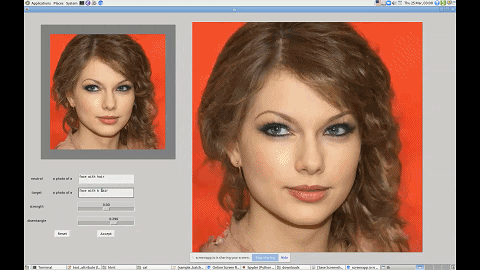
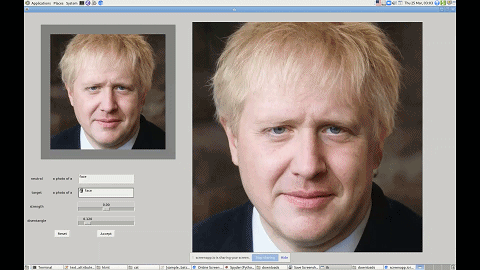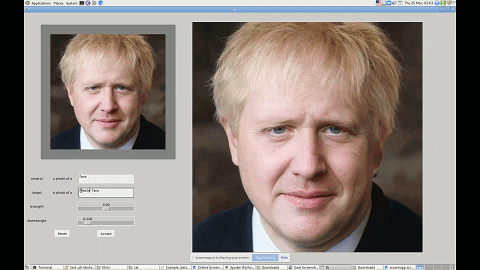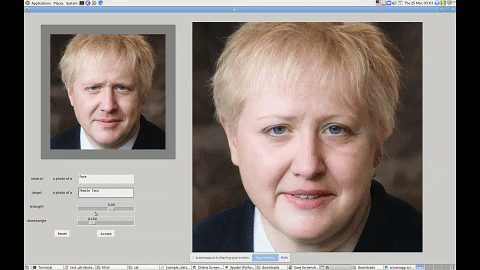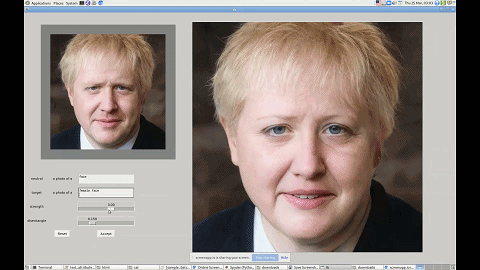
这一技术有着广泛的应用前景,比如帮短视频、图片 APP 打造一个能听懂人话的滤镜。无论你是想祛痘还是放大眼睛,只需要跟软件说一声就行了。

在作者栏,我们还看到了 Adobe 研究者的身影。如果 Adobe 将其加入 Photoshop,我们或许就不用自己动手修图了。

Standard Cognition(美国的一家自动结算解决方案提供商)联合创始人 David Valdman 指出,语言可能会是软件的下一代接口。

为了支持这一断言,他还收集了最近的一些话题、研究作为证据,比如特斯拉 AI 高级总监 Andrej Karpathy 等人讨论用自然语言给大模型下达指令;MIT 的研究者提出用文字控制图像某一区域的颜色等。
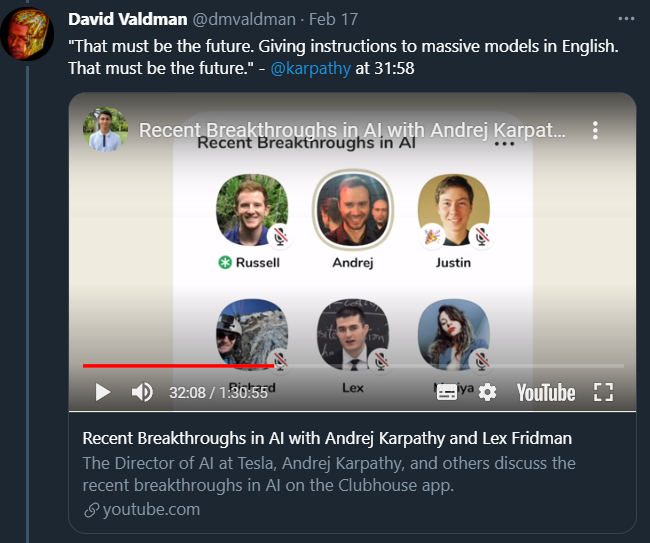
David Valdman 系列推文地址:https://twitter.com/dmvaldman/status/1358916558857269250
 图片来自论文《Paint by Word》。论文链接:https://arxiv.org/pdf/2103.10951.pdf
图片来自论文《Paint by Word》。论文链接:https://arxiv.org/pdf/2103.10951.pdf但这种趋势也存在一些问题,比如眼下的 AI 能不能完全听懂人话呢?或者人类需要创造一种全新的语言用于跟 AI 沟通?也许在未来,程序员不再敲代码,而是要输入一些类似口语却又不是口语的文字。

StyleGAN+CLIP=StyleCLIP
顾名思义,StyleCLIP 融合了 StyleGAN 和 CLIP 两种模型的特性。
GAN 模型的出现颠覆了图像生成领域,StyleGAN 更是其中的翘楚,可以生成极其逼真的图像。此外,研究者发现,StyleGAN 学到的中间隐空间拥有解耦特性,这使得利用预训练模型对合成图像以及真实图像执行各种各样的图像操作成为可能。
但对于用户来说,利用 StyleGAN 的强大表达能力来实现自己的意图并不容易。他们需要一个简单、直观的接口。现有的语义控制发现方法要么涉及手动检查,要么涉及大量带注释的数据,要么需要预训练的分类器。此外,后续操作通常是使用一个参数模型(如 StyleRig 中的 3DMM),通过在一个隐空间中沿着一个方向移动来执行。
总之,现有的控制只能按照预设的语义方向操作图像,严重限制了用户的创造力和想象力。每次要添加一个未映射的方向,都需要大量的手工工作和 / 或大量的注释数据。
在这篇论文中,研究者利用 OpenAI 最近推出的 CLIP(Contrastive Language-Image Pre-training)模型来支持基于文本的直观语义图像操作,既不限于预设的操作方向,也不需要额外的手工工作来发现新的 control。

StyleCLIP 的效果展示。红框中的内容是人类给出的修图要求,比如「莫西干头」、「卸妆」、「变可爱」、「变狮子」等。
论文链接:https://arxiv.org/pdf/2103.17249.pdf
项目链接:https://github.com/orpatashnik/StyleCLIP
CLIP 模型是 OpenAI 推出的基于文本对图片进行分类的模型。给出一组以语言形式表述的类别,CLIP 能够立即将一张图像与其中某个类别进行匹配,而且它不像标准神经网络那样需要针对这些类别的特定数据进行微调。在 ImageNet 基准上,CLIP 的性能超过 ResNet-50,在识别不常见图像任务中的性能远超 ResNet。
由于自然语言能够表达更加广泛的视觉概念,将 CLIP 与 StyleGAN 的强大生成能力相结合可以为图像操作打开更迷人的图景。具体来说,在本文中,研究者探索了三种将 CLIP 和 StyleGAN 相结合的技术:
1、以文本为指导的 latent 优化,其中 CLIP 模型被用作一个损失网络,这是一种通用方法,但需要几分钟的时间来进行优化,以对图片进行操作;
2、一个训练用于特定文本提示的 latent 残差映射器。在隐空间中给定一个起点(需要操作的输入图像),映射器在隐空间中产生一个局部步骤;
3、一种在 StyleGAN 的 style space 中将文本提示映射到输入无关(全局)方向(global direction)的方法,提供了对操作强度和解耦的控制。
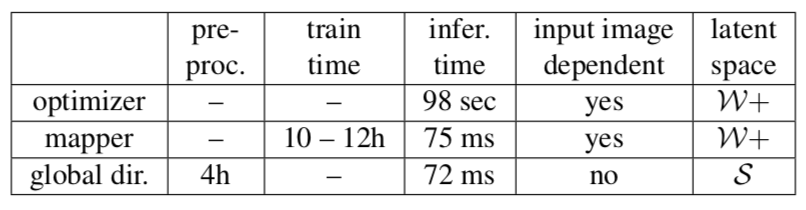
表 1: 优化器和映射器推断的 latent 步骤取决于输入图像,但是每个文本提示只进行一次训练。global direction 方法需要一次预处理,之后可应用于不同的(图像、文本提示)对。
效果评估
在评估过程中,研究者将这三种方法与其他方法进行对比,所有处理过的真实图像都使用 e4e 编码器进行了反转。
下图展示了三种文本驱动的人脸图像操作方法:latent mapper method,global direction method 和 TediGAN(此处使用的 TediGAN 来源于最近更新的官方实现,因此其与 CLIP 论文中提供的方法略有不同)。
第一组的指令是「特朗普化」,也是其中最复杂的指令了,基本上要包含金发、眯眼、张嘴、脸肿几个特征(懂的人自然懂)。global latent direction 能够捕捉到这些特征,但这些特征不是专属于特朗普的,相比之下,latent 映射器更能「听懂」指令。但在第三组指令「消除皱纹」中,映射器的效果不是很理想。
结论是,对于复杂和特定的属性 (特别是那些涉及身份的属性) ,映射器能够产生更好的结果。对于更简单或更常见的属性,global direction 就足够了。此外,总体来说,TediGAN 的生成结果在三个指令中都失败了。

随后,研究者对比了 global direction 和其他 StyleGAN 图像处理方法,包括 GANSpace [13]、 InterFaceGAN [41] 和 StyleSpace [50]。

这部分对比实验涉及的都是基本操作,比如发色和唇色。本文所提出方法的生成结果较为接近 StyleSpace [50] ,只改变目标属性,所有其他属性均保持不变。
在论文中,研究者还展示了本文方法与 StyleFLow [1] 的对比,StyleFlow 同时使用了多个属性分类器和回归值,因此只能操作有限的属性。而在生成结果质量接近的前提下,本文方法不需要额外的监督。
目前,本文方法还存在一定局限性,依赖于一个预训练的 StyleGAN 生成器和 CLIP 模型进行视觉语言嵌入,因此我们无法期望它生成预训练生成器理解范畴之外的东西。类似地,映射到未充分填充图像的 CLIP 空间区域的文本提示不能产生忠实反映提示语义的视觉操作。
研究者还发现,在视觉上比较多样化的数据集上进行跨度很大的操作是很难实现的。例如,虽然老虎很容易转化为狮子 ,但是在将老虎转化为狼时,就不那么成功了。

「我本是小脑斧,又不是北极狼……」
亚马逊云科技线上黑客松2021
这是一场志同道合的磨练,这是一场高手云集的组团竞技。秀脑洞、玩创意,3月26日至5月31日,实战的舞台为你开启,「亚马逊云科技线上黑客松2021」等你来战!
为了鼓励开发者的参与和创新,本次大赛为参赛者准备了丰厚的奖品,在一、二、三等奖之外,还特设prActIcal奖、creAtIve奖、锦鲤极客奖、阳光普照奖,成功提交作品的团队均可获赠奖品。

©THEEND
转载请联系本公众号获得授权